
Schritt-für-Schritt-Anleitung zur Bereitstellung von AnythingLLM mit OpenAI, Azure AI und Ollama
Hinweis: Um den vollen Nutzen aus diesem Blog zu ziehen, sollten Sie ein gutes Verständnis von Kubernetes und Helm haben. Wir werden wichtige Komponenten für eine erfolgreiche Retrieval-Augmented Generation (RAG)-Lösung besprechen, darunter den Embedder (wandelt Text in Vektoren um), die Vektordatenbank (speichert und sucht Einbettungen) und große Sprachmodelle (LLMs, die menschenähnlichen Text generieren).
Dieser Blog ist praxisorientiert mit praktischen Beispielen. Ein besonderer Dank geht an Mintplex Labs für AnythingLLM. Wenn Sie ihre Tools nützlich finden, geben Sie ihrem Projekt bitte einen ⭐️ auf GitHub.
INGRESS: Wenn Sie es über Ingress bereitstellen, denken Sie daran, die Größenbeschränkung für den Body mit Annotations zu erhöhen (z.B.
nginx.ingress.kubernetes.io/proxy-body-size: 10m). Andernfalls sind Sie auf das Hochladen von Dateien mit einer Größe von maximal 1 MB beschränkt.Ein großer Dank geht auch an Steve Golling, der mich mit AnythingLLM in Kontakt gebracht und die verschiedenen Setups mit mir eingerichtet hat!

Bild 1: AnythingLLM – Ganz viele Möglivhkeiten
Wir werden die vielen Möglichkeiten erkunden, die AnythingLLM durch verschiedene Setups bietet und dabei nur einen Bruchteil seines Potenzials aufzeigen. Abb. 1 zeigt nur eine kleine Auswahl an möglichen Lösungen. Mintplex Lab hat großartige Arbeit geleistet, diese Lösungen und verschiedene Konnektoren anzubieten. Für eine umfassende Übersicht über alle möglichen Lösungen, einschließlich LLMs, Embedders und Vektordatenbanken, besuchen Sie ihre Website.
Aber zuerst…Warum❓

Bild 2: Why? Why? Why? ..Oh, that’s why (I hope you get the same felling after reading the blog)?
Viele Unternehmen stehen heute vor großen Herausforderungen, wenn sie fortschrittliche Sprachmodelle wie ChatGPT nutzen möchten. Europäische Unternehmen müssen die strengen GDPR-Datenschutzgesetze einhalten, was die Nutzung von Cloud-Diensten wie OpenAI erschwert. Darüber hinaus schränken interne Richtlinien oder gesetzliche Vorschriften oft die Nutzung von OpenAI ein. Viele Unternehmen bevorzugen es zudem, ihre eigenen Chatbots zu hosten, um die volle Kontrolle über Daten und Anpassungen zu behalten. Aufgrund dieser Herausforderungen ist die einfache Nutzung der Chat-Funktionalität von Diensten wie OpenAI für viele Unternehmen nicht praktikabel.
Und wie wollen Sie dieses Problem lösen?
Hinweis: Ich werde Abkürzungen wie base-x, base-x-embedder und base-x-embedder-vdb verwenden, um die Bezugnahme auf die Setups zu vereinfachen, insbesondere später in der Benutzeroberfläche.
Ich werde Ihnen zeigen, wie Sie mit AnythingLLM auf Kubernetes eine vollständige Lösung mit verschiedenen Setups bereitstellen:
- AnythingLLM native Komponenten mit OpenAI LLM -> base-0
- AnythingLLM native Komponenten mit OpenAI LLM und OpenAI Embedder (text-embedding-ada-02) -> base-0-embedder
- AnythingLLM mit OpenAI LLM, OpenAI Embedder (text-embedding-ada-02) und ChromaDB (Vektor-Datenbank) -> **base-0-embedder-vdb **
- AnythingLLM native Komponenten mit Azure OpenAI LLM -> base-1
- AnythingLLM native Komponenten mit Azure OpenAI LLM und Azure OpenAI Embedder (text-embedding-ada-02) -> **base-1-embedder **
- AnythingLLM mit Azure OpenAI LLM, OpenAI Embedder (text-embedding-ada-02) und ChromaDB (Vektor-Datenbank) -> base-1-embedder-vdb
- AnythingLLM native Komponenten mit Ollama LLM -> **base-2 **
- AnythingLLM native Komponenten mit Ollama LLM und Ollama Embedder (nomic-embed-text) -> base-2-embedder
- AnythingLLM mit Ollama LLM, Ollama Embedder (nomic-embed-text) und ChromaDB (Vektor-Datenbank) -> base-2-embedder-vdb
Für jedes Setup werde ich detaillierte Anleitungen und Beispielcode bereitstellen, um Ihnen bei der Integration verschiedener Komponenten wie Sprachmodelle, Embeddings und Vektordatenbanken zu helfen. Wir werden auch die Ergebnisse basierend auf Retrieval-Augmented Generation (RAG) und unseren eigenen Dokumenten vergleichen, um zu sehen, wie gut jedes Setup funktioniert. Wir werden jedes Mal die gleiche Frage stellen: Welcher Service wird angeboten?
Als Nächstes werde ich versuchen, einige Definitionen zu erklären, um das Verständnis zu erleichtern.
0. Definitionen und Begriffe
Bevor wir in die technischen Details eintauchen, werden wir einige grundlegende Definitionen und Begriffe erklären, um das Verständnis zu erleichtern. Dies umfasst, was LLMs, Embeddings und Vektordatenbanken sind und wie Kubernetes und Helm funktionieren.
Großes Sprachmodell (LLM)
Ein Großes Sprachmodell (LLM) ist ein fortschrittliches KI-System, das darauf ausgelegt ist, menschliche Sprache zu verstehen und zu generieren. Beispiele hierfür sind OpenAIs GPT-3. Diese Modelle werden mit großen Mengen an Textdaten trainiert und können eine Vielzahl von Sprachaufgaben ausführen, von der Beantwortung von Fragen bis hin zum Verfassen von Aufsätzen.
Embedder
Ein Embedder ist ein Tool oder Modell, das Text in numerische Vektoren umwandelt. Diese Vektoren stellen den Text so dar, dass er für Computer einfacher zu verstehen und zu verarbeiten ist. Embeddings sind entscheidend für Aufgaben wie Ähnlichkeitssuche und Clustering. Ein Beispiel für einen Embedder ist OpenAIs text-embedding-ada-02.
Vektordatenbank (Vector DB)
Eine Vektordatenbank ist eine spezialisierte Datenbank, die dafür ausgelegt ist, Vektorembeddings effizient zu speichern und abzufragen. Sie ermöglicht schnelle Ähnlichkeitssuchen und wird oft in Anwendungen wie Empfehlungssystemen und semantischer Suche eingesetzt. ChromaDB ist ein Beispiel für eine Vektordatenbank.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) ist eine Technik, die retrieval-basierte und generation-basierte Methoden kombiniert, um die Leistung von Sprachmodellen zu verbessern. Dabei werden relevante Dokumente oder Datenpunkte abgerufen, bevor eine Antwort generiert wird, was für genauere und kontextbezogenere Ergebnisse sorgt.
Kubernetes
Kubernetes ist eine Open-Source-Plattform zur Automatisierung der Bereitstellung, Skalierung und Verwaltung containerisierter Anwendungen. Sie hilft bei der Verwaltung groß angelegter Anwendungen durch Funktionen wie Lastverteilung, Skalierung und automatisierte Rollouts.
Helm
Helm ist ein Paketmanager für Kubernetes, der die Bereitstellung und Verwaltung von Anwendungen auf Kubernetes vereinfacht. Es verwendet Helm-Charts, vorgefertigte Anwendungsressourcen, um Anwendungen einfach bereitzustellen und zu verwalten.
Privates LLM
Ein privates LLM ist ein großes Sprachmodell, das in der eigenen Infrastruktur eines Unternehmens gehostet und verwaltet wird. Dies stellt sicher, dass alle vom Modell verarbeiteten Daten unter der Kontrolle des Unternehmens bleiben, um Datenschutz- und Compliance-Anforderungen zu erfüllen.
AnythingLLM
AnythingLLM ist ein vielseitiges Framework von Mintplex Labs, das die Integration und Bereitstellung verschiedener LLMs, Embeddings und Vektordatenbanken ermöglicht. Es bietet Konnektoren und Tools, um Komponenten einfach auszutauschen und angepasste KI-Lösungen zu erstellen.
Im nächsten Abschnitt richten wir die Umgebung für die Bereitstellung der verschiedenen Anwendungsfälle ein.
1. Umgebung einrichten: Installation von Helm und Helm-Chart für Anything-LLM
Ich werde einen Azure Kubernetes Service (AKS) als Kubernetes Lösung verwenden. Sie können jede beliebige Lösung nutzen. Ich verwende AKS, da ich einen GPU-Knotenpool für das Ollama-Setup benötige.
1.1 Helm installieren und Version überprüfen
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
helm version
#output like:
v3.15.31.2 Anything-LLM über Helm bereitstellen
Zuerst das Helm-Chart hinzufügen.
helm repo add anything-llm https://la-cc.github.io/anything-llm-helm-chartDann das Repository aktualisieren, um sicherzustellen, dass die neueste Version verfügbar ist.
helm repo updateNun können Sie das Manifest des Helm-Charts installieren oder vorab erstellen. Ich werde das Manifest vorab erstellen und direkt anwenden, um einen besseren Überblick über die kommende Konfigurations-Einrichtung über eine values.yaml-Datei zu erhalten. Testen Sie, ob Sie die Dummy-Werte mit folgendem Befehl vorab erstellen können:
helm template anything-llm-hks anything-llm/anything-llm
#output like
---
# Source: anything-llm/templates/namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: anything-llm-hks
---
# Source: anything-llm/templates/secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: anything-llm-secret
namespace: anything-llm-hks
labels:
helm.sh/chart: anything-llm-0.2.1
app.kubernetes.io/name: anything-llm
app.kubernetes.io/instance: anything-llm-hks
app.kubernetes.io/version: 0.0.5
app.kubernetes.io/managed-by: Helm
....
Aber wir werden die values.yaml mit benutzerdefinierten Werten überschreiben. Sie können die Werte mit folgendem Befehl abrufen:
helm show values anything-llm/anything-llm > values.yamlDieser Guide richtet Ihre Umgebung ein, installiert Helm und stellt das Anything-LLM Helm-Chart auf einem AKS-Cluster bereit. Nun haben wir alles, um verschiedene Kombinationen zu implementieren.
Wir beginnen im nächsten Teil mit der einfachsten Konfiguration und versuchen, so viele native Komponenten wie möglich zu verwenden.
AnythingLLM native Komponenten mit OpenAI LLM (base-0)
Wichtig: Wir werden zur Vereinfachung ein templated
secret.yaml-File im Helm-Chart verwenden. Verwenden Sie diese Methode nicht in Produktionsumgebungen. Erstellen Sie stattdessen ein Kubernetes-Secret und referenzieren Sie es. Das Helm-Chart ermöglicht es, ein Secret über dessen Namen zu referenzieren.
Wir werden die Konfiguration und den Einsatz wie in Abbildung 3 dargestellt einrichten und bereitstellen.

Bild 3: AnythingLLM native Komponenten mit OpenAI LLM -> base-0
Lassen Sie uns beginnen und die abgerufene values.yaml aus der vorherigen Umgebungsinstallation anpassen.
Dazu müssen wir die values.yaml wie folgt modifizieren:
chromadb:
enabled: false
chromadb:
auth:
enabled: false
service:
type: ClusterIP
# -- Override the full name of the chart.
fullnameOverride: "anything-llm-hks"
# -- Ingress configuration.
ingress:
# -- Enable ingress.
enabled: true
# -- Ingress annotations.
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-dns
cert-manager.io/renew-before: 360h
# -- Ingress hosts.
hosts:
- host: llm-hks.example.com
paths:
- path: /
pathType: Prefix
# -- TLS configuration for ingress.
tls:
- hosts:
- llm-hks.example.com
secretName: anything-llm-tls
# -- Configuration for the application.
config:
STORAGE_DIR: "/app/server/storage"
EMBEDDING_MODEL_PREF: "nomic-embed-text:latest"
EMBEDDING_MODEL_MAX_CHUNK_LENGTH: "8192"
# EMBEDDING_MODEL_PREF: "text-embedding-ada-002"
# EMBEDDING_ENGINE: 'openai'
VECTOR_DB: "lancedb"
WHISPER_PROVIDER: "local"
TTS_PROVIDER: "native"
LLM_PROVIDER: 'openai'
# -- Secret configuration.
secret:
# -- Enable secrets.
enabled: true
# -- Name of the secret, if not set, a secret is generated.
name: ""
# -- Secret data.
data:
AUTH_TOKEN: "r6.."
JWT_SECRET: "CM..."
OPEN_AI_KEY: "sk-pr..."
Wir konfigurieren den LLM-Anbieter auf OpenAI, fügen den OpenAI-Schlüssel für den API-Zugang hinzu und erstellen ein Authentifizierungs-Token. Dies ist erforderlich, da wir die Anything-LLM-Benutzeroberfläche über ein Ingress bereitstellen werden, wodurch sie im Internet zugänglich wird.
Jetzt deployen wir es!
helm template anything-llm-hks anything-llm/anything-llm -f values.yaml | k apply -f -und überprüfen, ob der Pod läuft:
kubectl get pods -n anything-llm-hks
NAME READY STATUS RESTARTS AGE
anything-llm-hks-658df8dc65-tssd8 1/1 Running 0 34sSchauen wir, ob wir die richtige Konfiguration über die Anything-LLM-UI bereitgestellt haben:
Bild 4: Überprüfen der bereitgestellten Konfiguration
Lassen Sie uns nun unsere Daten hochladen und die Frage stellen: Welcher Service wird angeboten?

Bild 5: Welcher Service wird angeboten? Ohne Dokumente und mit Dokumenten (base-0).
Wie Sie sehen, erhalten wir ohne Einbettung unserer Daten generische Antworten. Nach dem Hochladen und Vektorisieren unseres Dokuments erhalten wir spezifische Antworten.
Im nächsten Teil verwenden wir den Embedder von OpenAI namens text-embedding-ada-002.
AnythingLLM native Komponenten mit OpenAI LLM und OpenAI Embedder (text-embedding-ada-02) -> base-0-embedder
Wir ersetzen den nativen Anything-LLM-Embedder (nomic-embed-text) durch OpenAI text-embedding-ada-002.
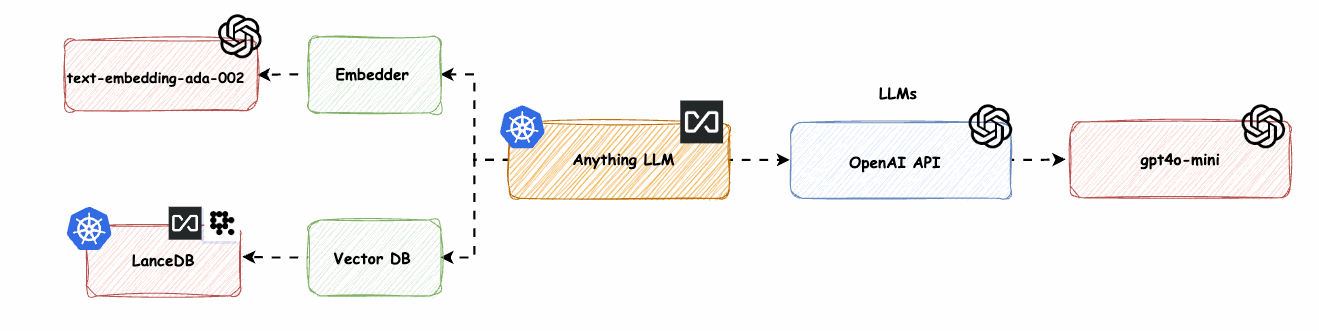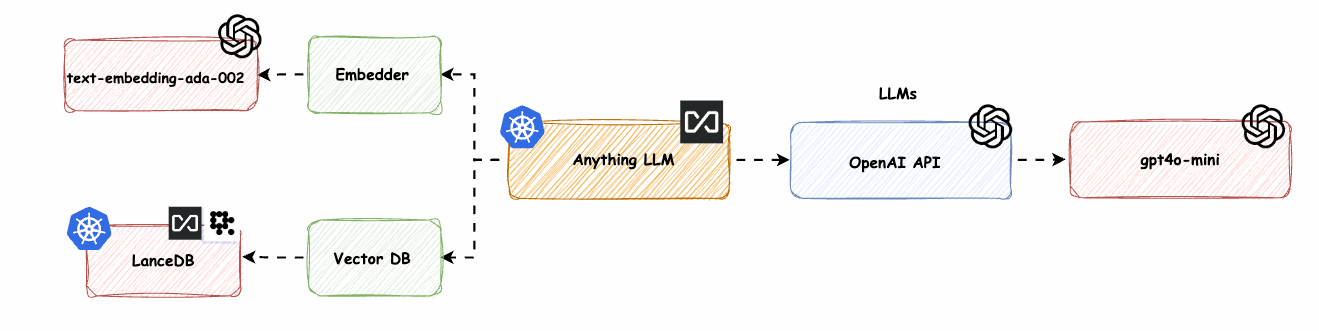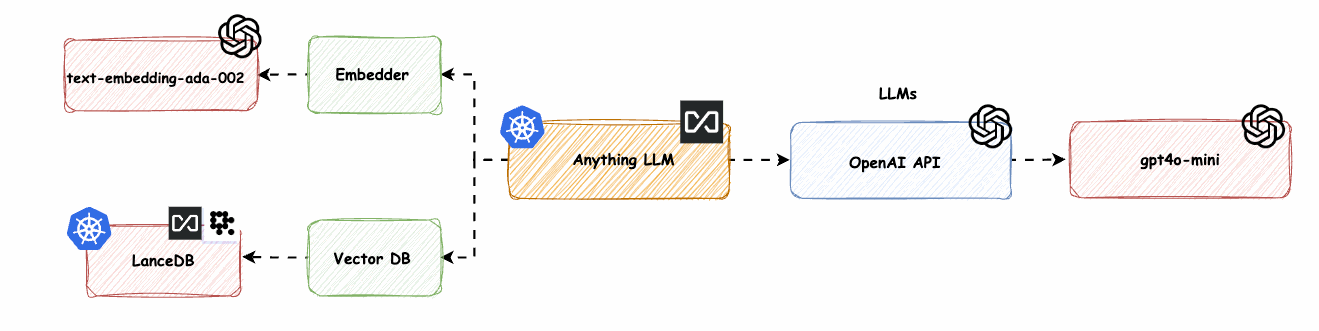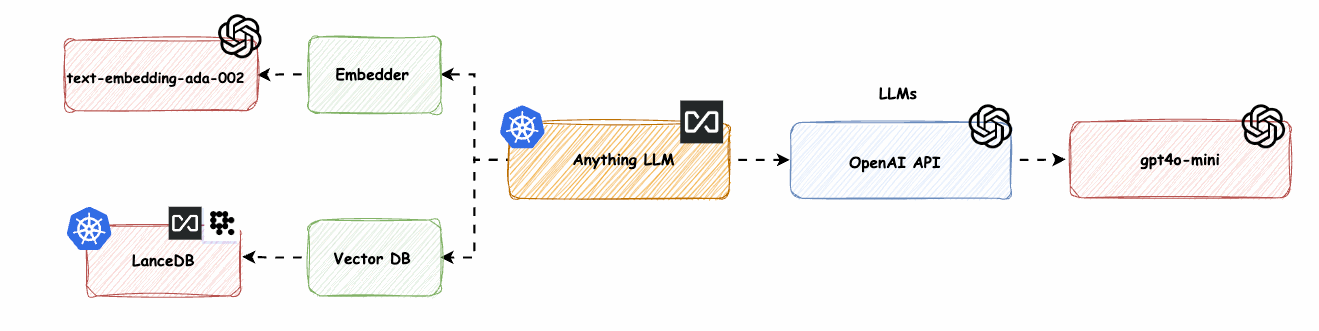
Bild 6: AnythingLLM native Komponenten mit OpenAI LLM und OpenAI Embedder (text-embedding-ada-02) -> base-0-embedder
Dazu müssen wir die values.yaml folgendermaßen anpassen:
chromadb:
enabled: false
chromadb:
auth:
enabled: false
service:
type: ClusterIP
# -- Override the full name of the chart.
fullnameOverride: "anything-llm-hks"
# -- Ingress-Konfiguration.
ingress:
# -- Ingress aktivieren.
enabled: true
# -- Ingress-Anmerkungen.
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-dns
cert-manager.io/renew-before: 360h
# -- Ingress-Hosts.
hosts:
- host: llm-hks.example.com
paths:
- path: /
pathType: Prefix
# -- TLS-Konfiguration für Ingress.
tls:
- hosts:
- llm-hks.example.com
secretName: anything-llm-tls
# -- Konfiguration für die Anwendung.
config:
STORAGE_DIR: "/app/server/storage"
# EMBEDDING_MODEL_PREF: "nomic-embed-text:latest"
EMBEDDING_MODEL_MAX_CHUNK_LENGTH: "8192"
EMBEDDING_MODEL_PREF: "text-embedding-ada-002"
EMBEDDING_ENGINE: 'openai'
VECTOR_DB: "lancedb"
WHISPER_PROVIDER: "local"
TTS_PROVIDER: "native"
LLM_PROVIDER: 'openai'
# -- Secret-Konfiguration.
secret:
# -- Secrets aktivieren.
enabled: true
# -- Name des Secrets, falls nicht gesetzt, wird ein Secret generiert.
name: ""
# -- Secret-Daten.
data:
AUTH_TOKEN: "r6.."
JWT_SECRET: "CM..."
OPEN_AI_KEY: "sk-pr..."Wir ersetzen EMBEDDING_MODEL_PREF und fügen EMBEDDING_ENGINE hinzu.
Jetzt können wir die Konfiguration bereitstellen!
helm template anything-llm-hks anything-llm/anything-llm -f values.yaml | k apply -f -Nun laden wir unsere Daten hoch und stellen die Frage: Welcher Service wird angeboten?
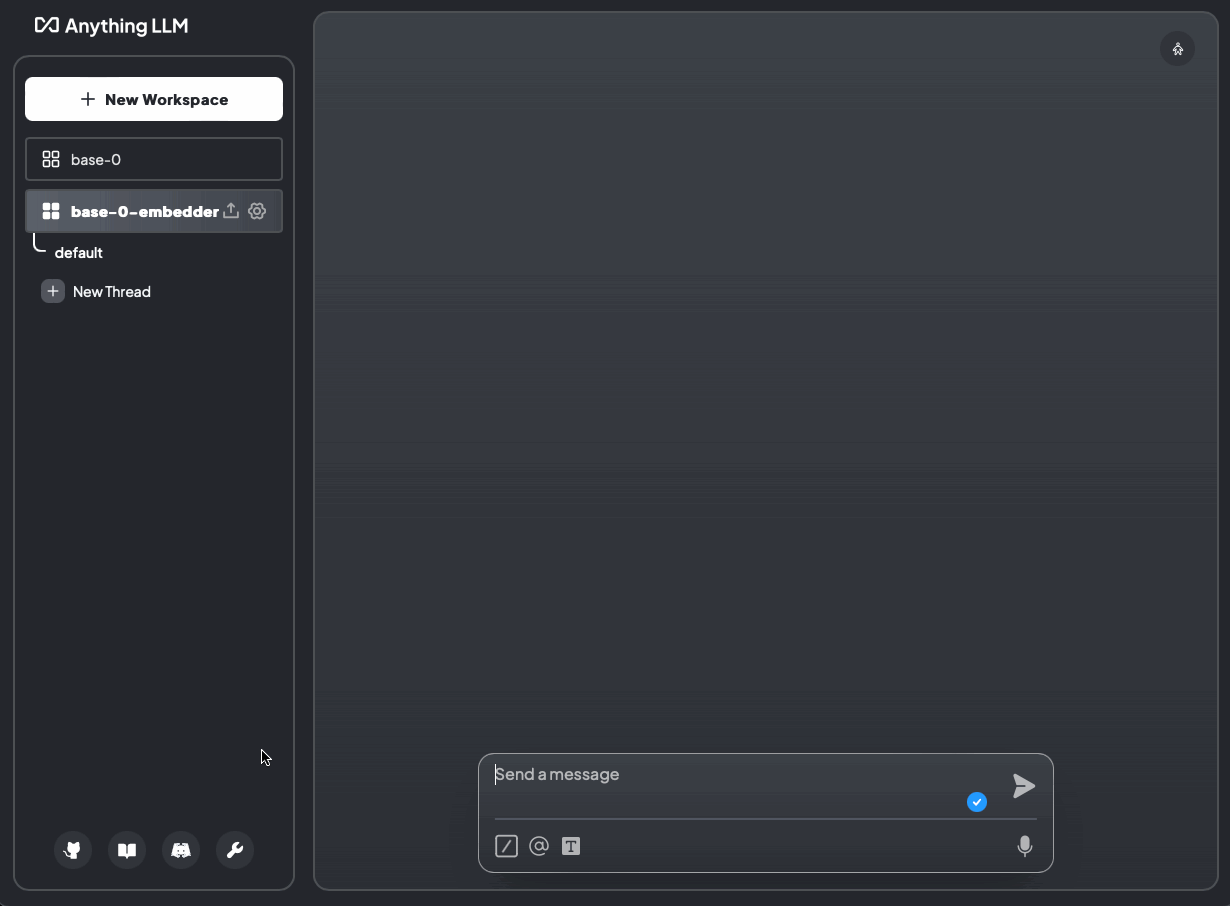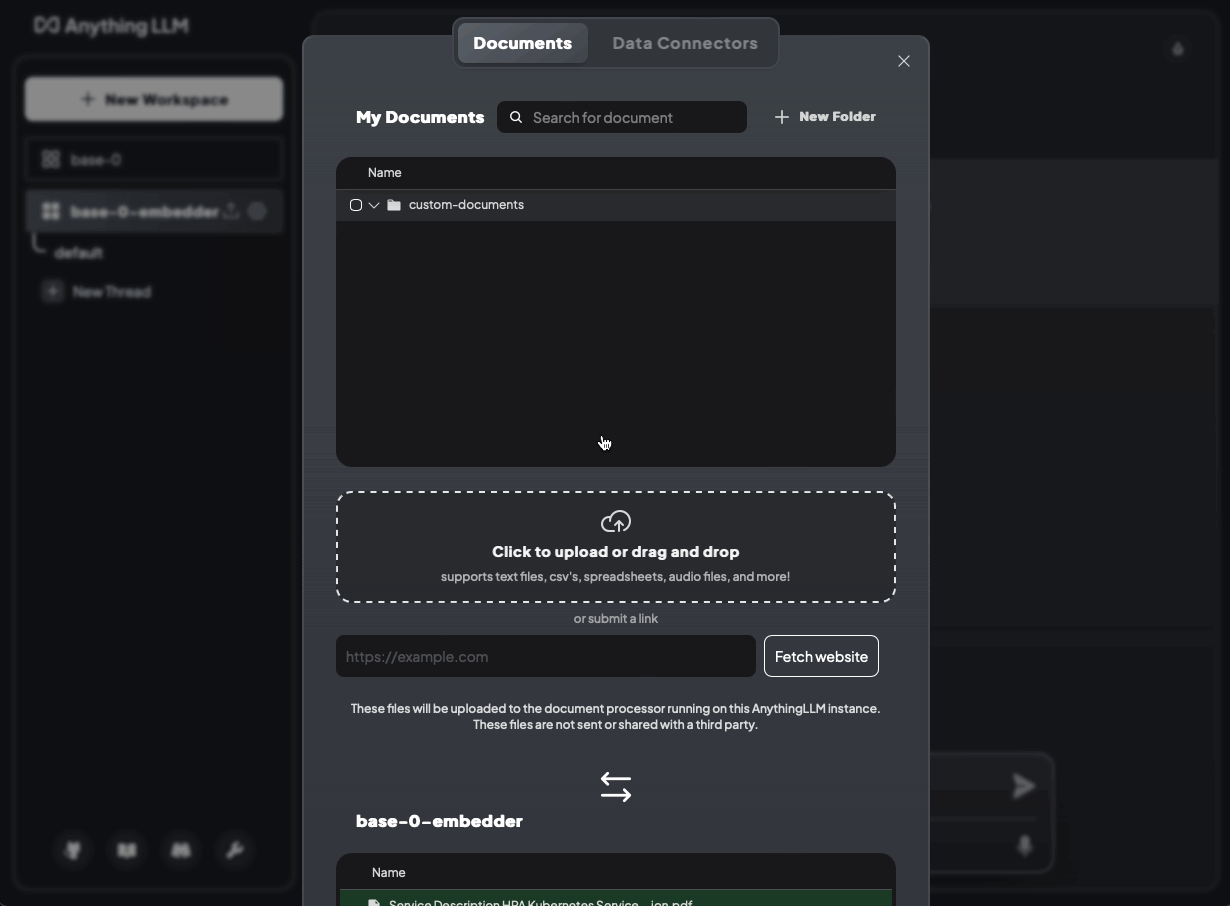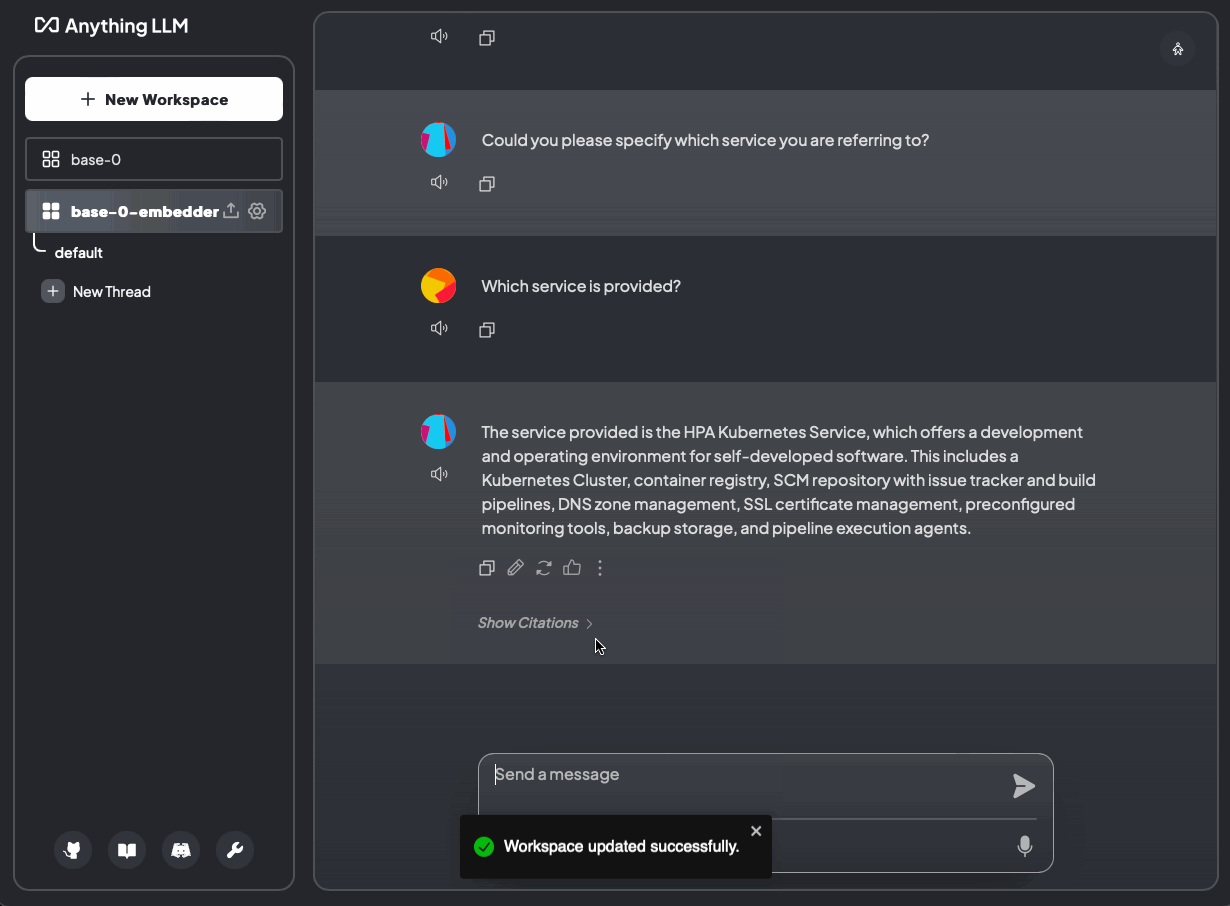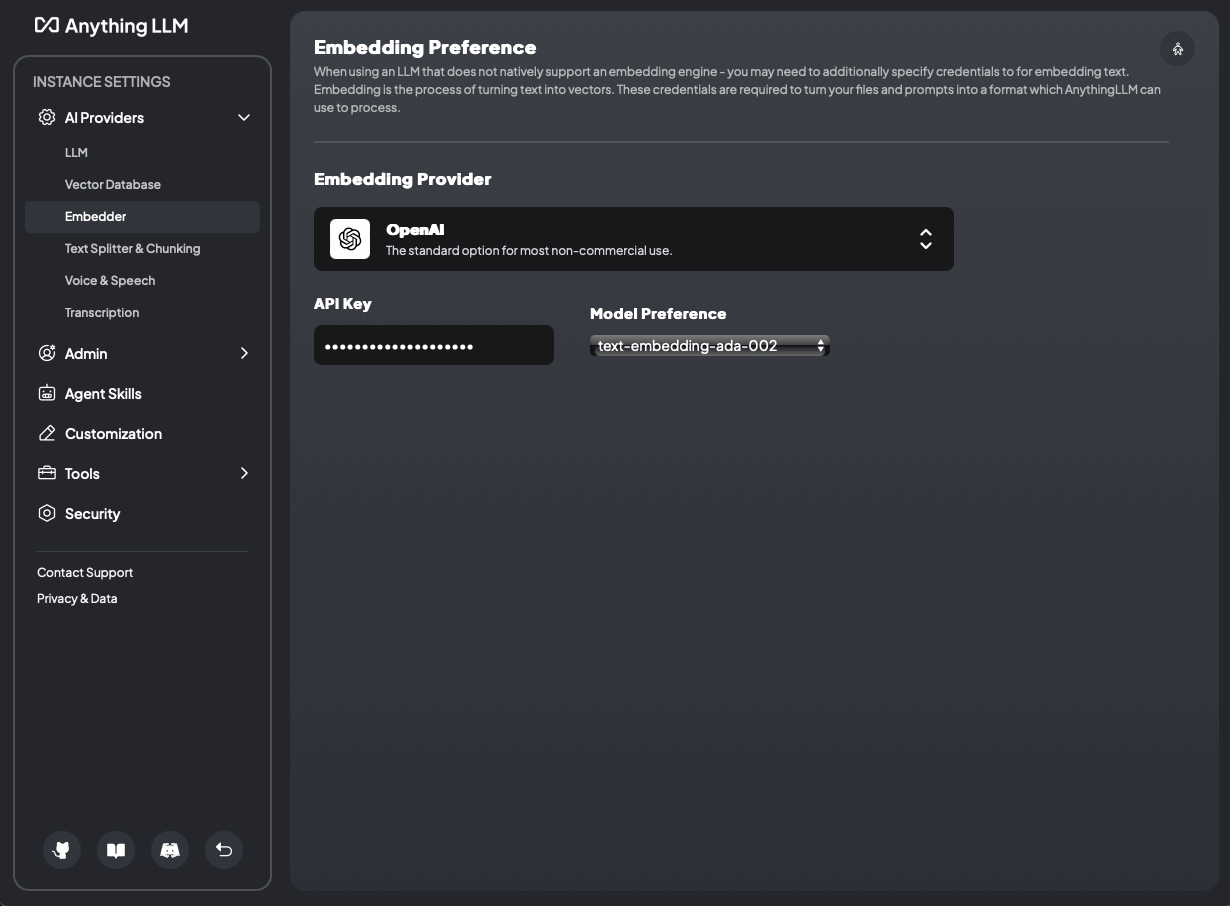
Abb. 7: Welcher Service wird angeboten? Ohne Dokumente und mit Dokumenten (base-0-embedder)
Sie können sehen, dass der OpenAI-Embedder schneller arbeitet. Außerdem erreicht der ada-02-Embedder bei Vergleichsreferenzen in den Dokumenten 77 %, während der nomic-Embedder 30–43 % erreicht. Der ada-02-Embedder scheint auch den Kontext besser zu verstehen und zu behalten, wenn er Fragen beantwortet.
Im nächsten Teil werden wir ChromaDB auf dem Kubernetes-Cluster bereitstellen.
AnythingLLM mit OpenAI LLM und OpenAI Embedder (text-embedding-ada-02) und ChromaDB (Vector DB) -> base-0-embedder-vdb
Wir werden den nativen Anything-LLM (nomic-embed-text) Embedder mit dem OpenAI text-embedding-ada-002 und die LanceDB durch ChromaDB ersetzen.
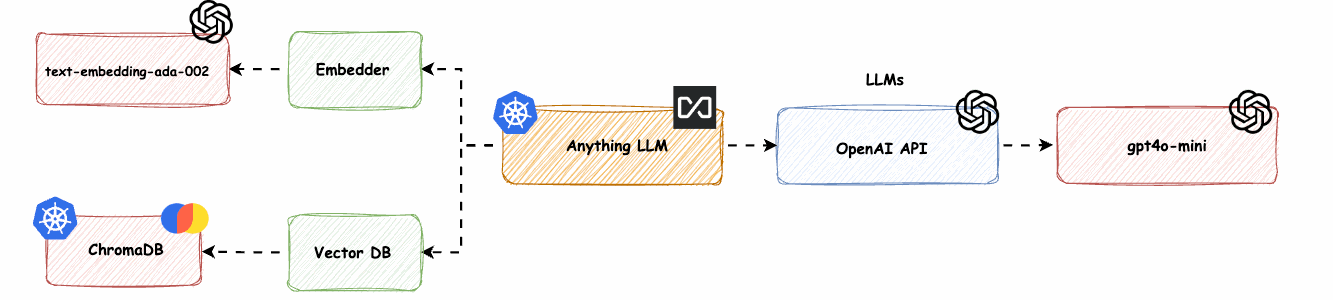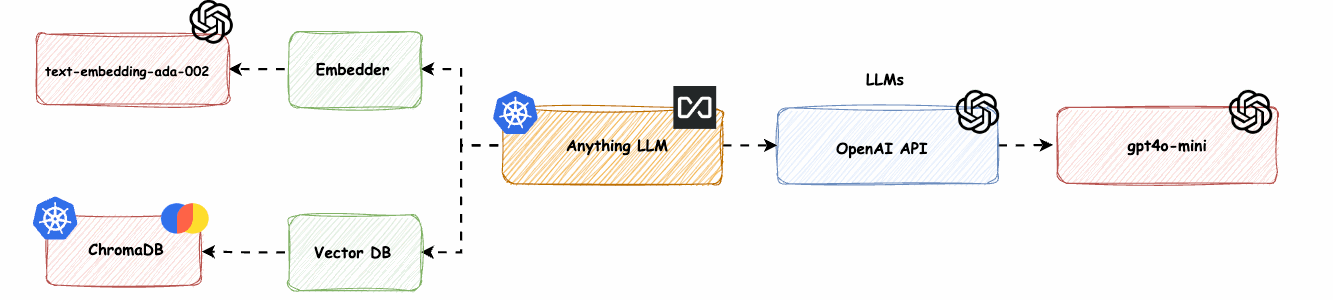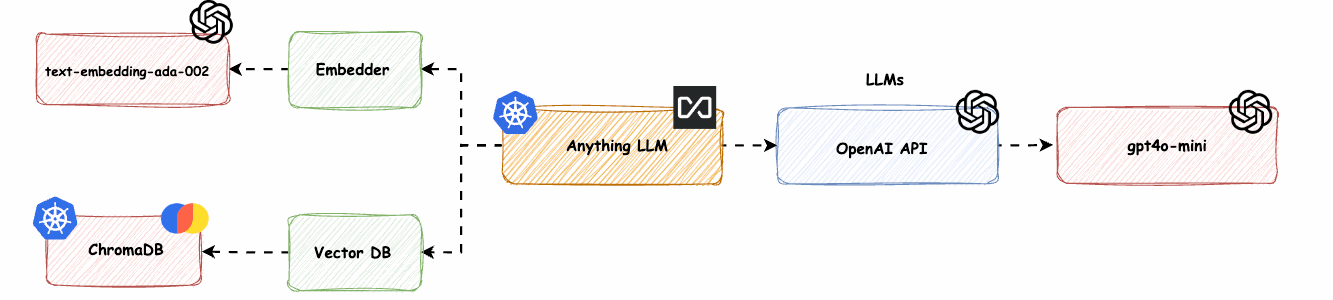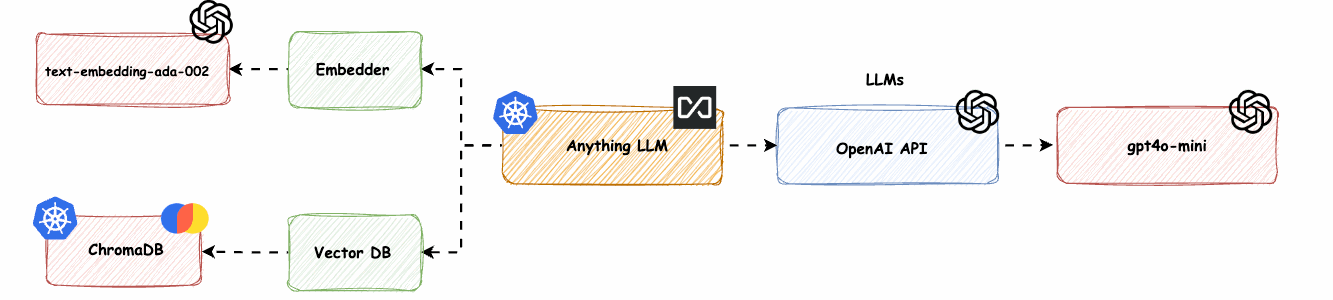
Abb. 8: AnythingLLM mit OpenAI LLM, OpenAI Embedder (text-embedding-ada-02) und ChromaDB (Vector DB) -> base-0-embedder-vdb
Wir müssen die values.yaml wie folgt anpassen:
chromadb:
enabled: true
chromadb:
auth:
enabled: false
service:
type: ClusterIP
# -- Override the full name of the chart.
fullnameOverride: "anything-llm-hks"# -- Ingress configuration.
ingress:
# -- Enable ingress.
enabled: true
# -- Ingress annotations.
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-dns
cert-manager.io/renew-before: 360h
# -- Ingress hosts.
hosts:
- host: llm-hks.example.com
paths:
- path: /
pathType: Prefix
# -- TLS configuration for ingress.
tls:
- hosts:
- llm-hks.example.com
secretName: anything-llm-tls
# -- Configuration for the application.
config:
STORAGE_DIR: "/app/server/storage"
# EMBEDDING_MODEL_PREF: "nomic-embed-text:latest"
EMBEDDING_MODEL_MAX_CHUNK_LENGTH: "8192"
EMBEDDING_MODEL_PREF: "text-embedding-ada-002"
EMBEDDING_ENGINE: 'openai'
VECTOR_DB: "chroma"
WHISPER_PROVIDER: "local"
TTS_PROVIDER: "native"
LLM_PROVIDER: 'openai'
# -- Secret configuration.
secret:
# -- Enable secrets.
enabled: true
# -- Name of the secret, if not set, a secret is generated.
name: ""
# -- Secret data.
data:
AUTH_TOKEN: "r6.."
JWT_SECRET: "CM..."
OPEN_AI_KEY: "sk-pr..."
CHROMA_ENDPOINT: http://anything-llm-hks-chromadb:8000Wir ändern VECTOR_DB, fügen CHROMA_ENDPOINT hinzu und setzen enabled auf true.
Jetzt deployen wir es!
helm template anything-llm-hks anything-llm/anything-llm -f values.yaml | k apply -f -Nun laden wir unsere Daten hoch und fragen: “Welcher Service wird angeboten?”
Bild 11: Welcher Service wird angeboten? Ohne Dokumente und mit Dokumenten (base-1)
Im nächsten Abschnitt verwenden wir den ada02-Embedder anstelle von nomic.
AnythingLLM native Komponenten mit Azure OpenAI LLM und Azure OpenAI Embedder (text-embedding-ada-02) -> base-1-embedder
Wir ersetzen den nativen Anything-LLM-Embedder (nomic-embed-text) mit Azure OpenAI text-embedding-ada-002.
Bild 12: AnythingLLM native Komponenten mit Azure OpenAI LLM -> base-1-embedder
Wir müssen die values.yaml wie folgt anpassen:
chromadb:
enabled: true
chromadb:
auth:
enabled: false
service:
type: ClusterIP
# -- Override the full name of the chart.
fullnameOverride: "anything-llm-hks"
# -- Ingress-Konfiguration.
ingress:
# -- Aktivieren des Ingress.
enabled: true
# -- Ingress-Anmerkungen.
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-dns
cert-manager.io/renew-before: 360h
# -- Ingress-Hosts.
hosts:
- host: llm-hks.example.com
paths:
- path: /
pathType: Prefix
# -- TLS-Konfiguration für Ingress.
tls:
- hosts:
- llm-hks.example.com
secretName: anything-llm-tls
# -- Konfiguration für die Anwendung.
config:
STORAGE_DIR: "/app/server/storage"
# EMBEDDING_MODEL_PREF: "nomic-embed-text:latest"
EMBEDDING_MODEL_MAX_CHUNK_LENGTH: "8192"
EMBEDDING_MODEL_PREF: "ada-002"
EMBEDDING_ENGINE: 'azure'
VECTOR_DB: "lancedb"
WHISPER_PROVIDER: "local"
TTS_PROVIDER: "native"
LLM_PROVIDER: 'azure'
AZURE_OPENAI_ENDPOINT: https://xxx-interface.openai.azure.com/
# -- Geheimniskonfiguration.
secret:
# -- Aktivieren von Secrets.
enabled: true
# -- Name des Secrets, falls nicht gesetzt, wird ein Secret generiert.
name: ""
# -- Geheimdaten.
data:
AUTH_TOKEN: "r6.."
JWT_SECRET: "CM..."
AZURE_OPENAI_KEY: "sk-pr..."
CHROMA_ENDPOINT: http://anything-llm-hks-chromadb:8000
Wir ändern VECTOR_DB, fügen CHROMA_ENDPOINT hinzu und setzen enabled auf true.
Nun lasst uns die Bereitstellung durchführen:
helm template anything-llm-hks anything-llm/anything-llm -f values.yaml | k apply -f -Laden wir nun unsere Daten hoch und fragen: “Welcher Service wird angeboten?”
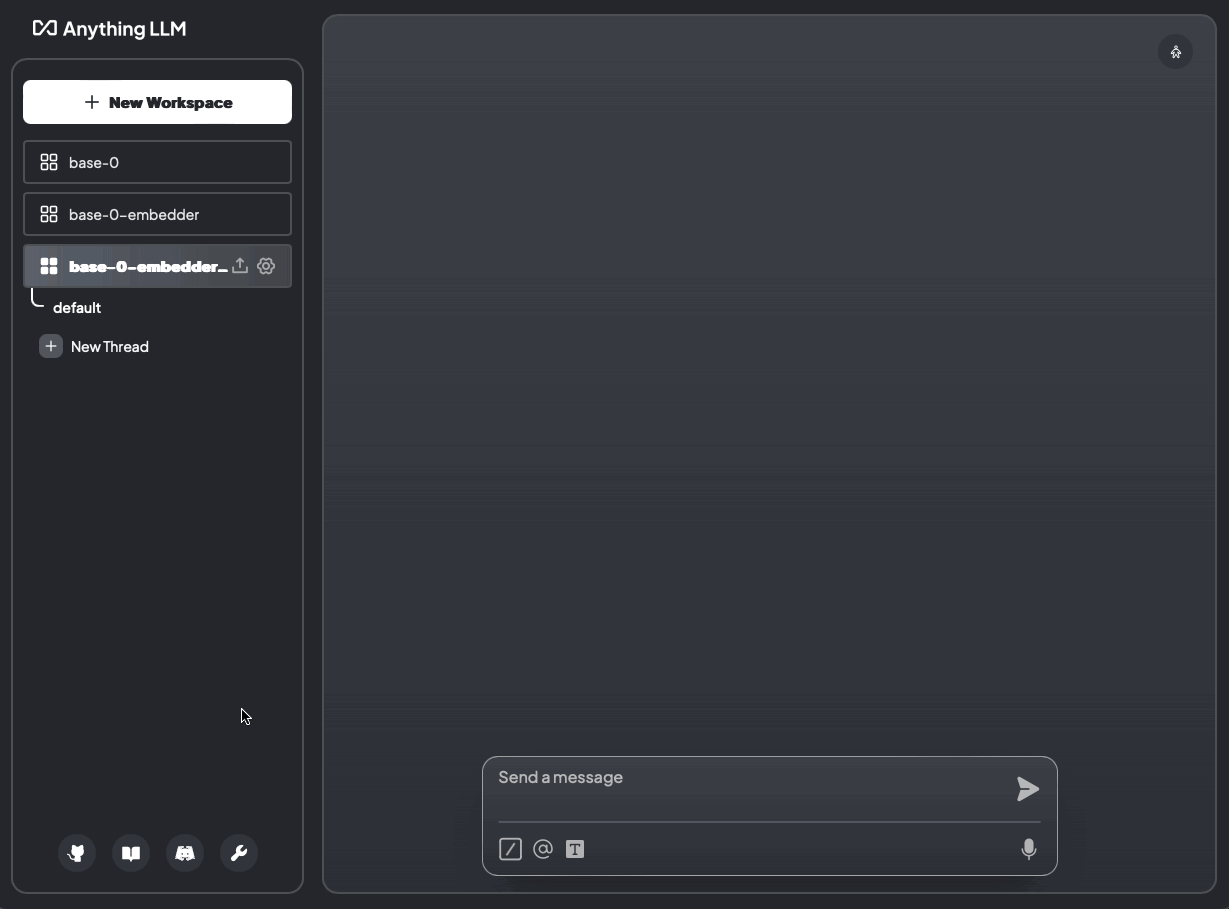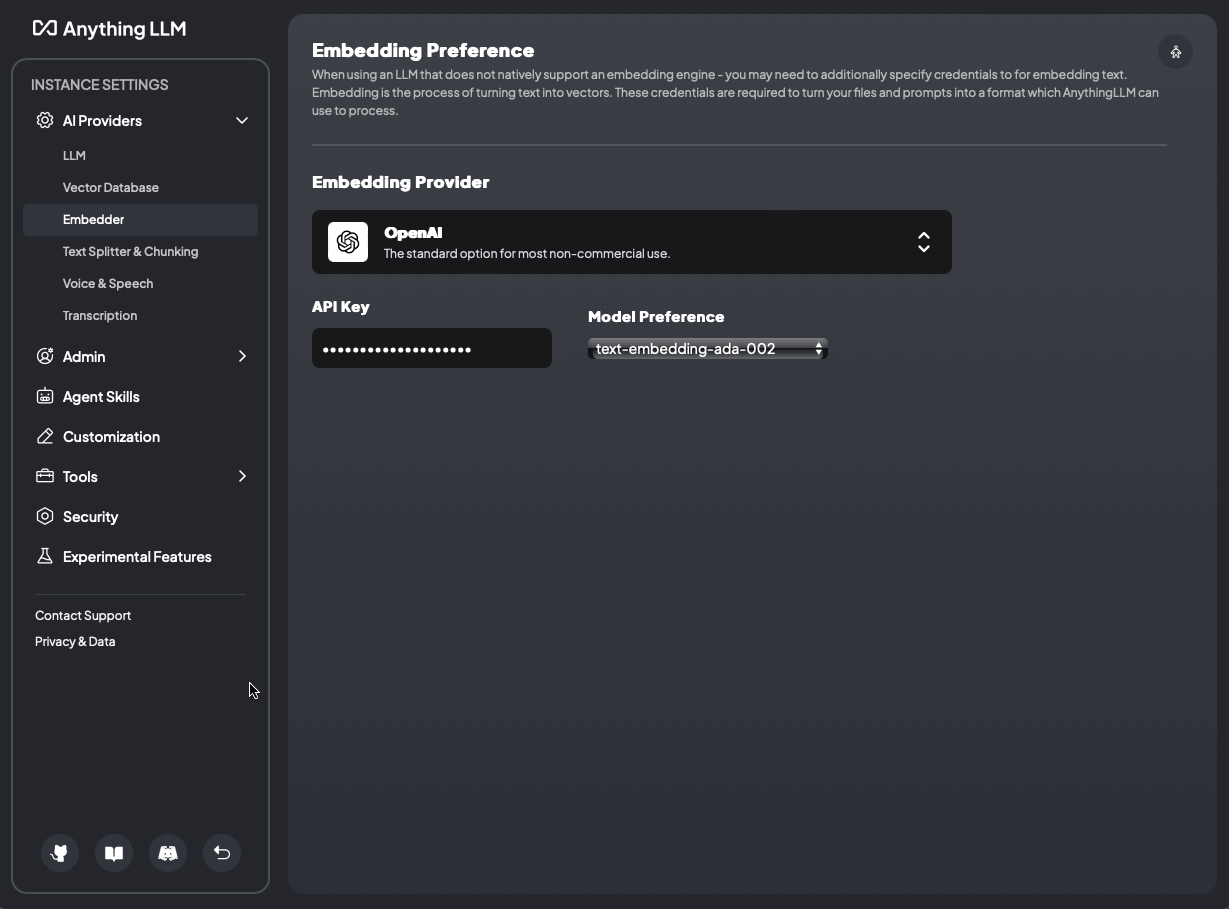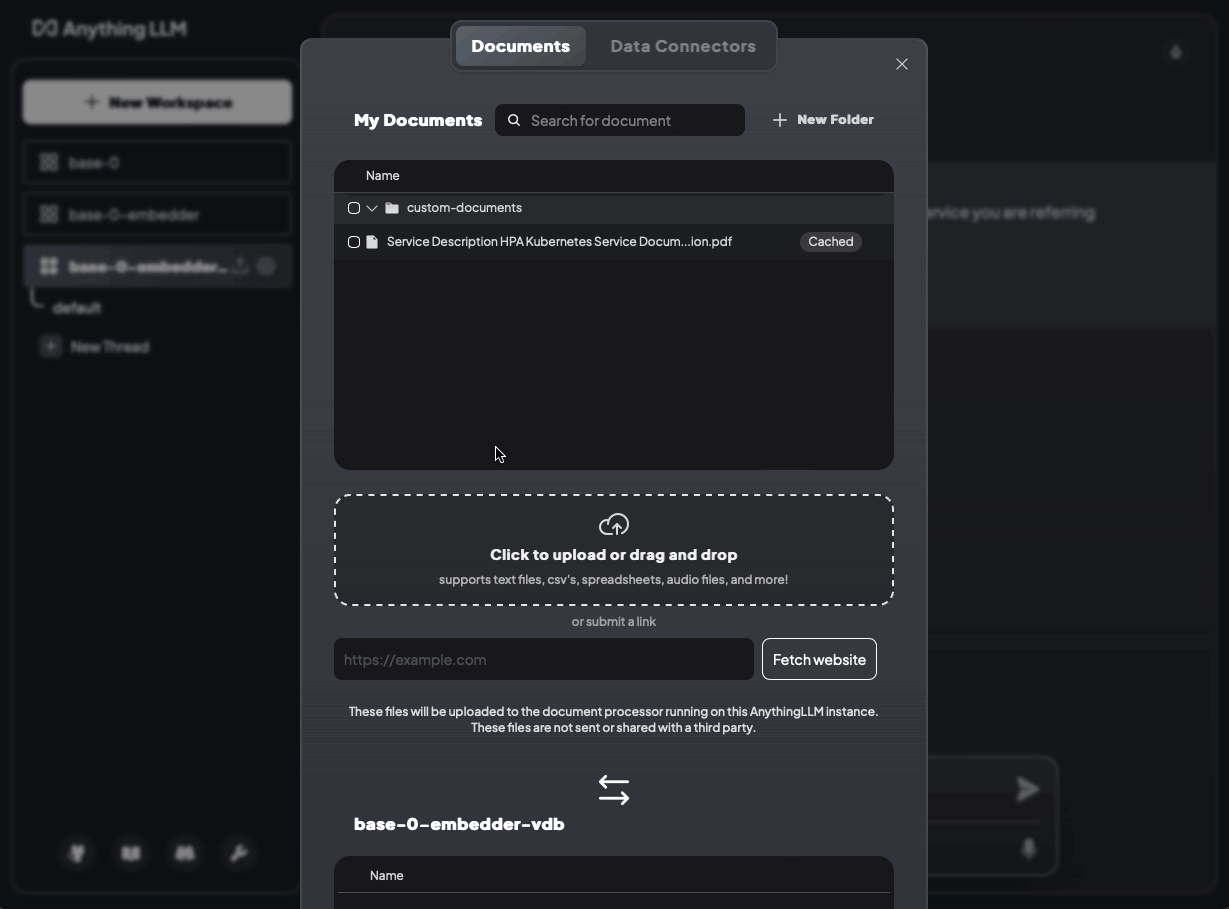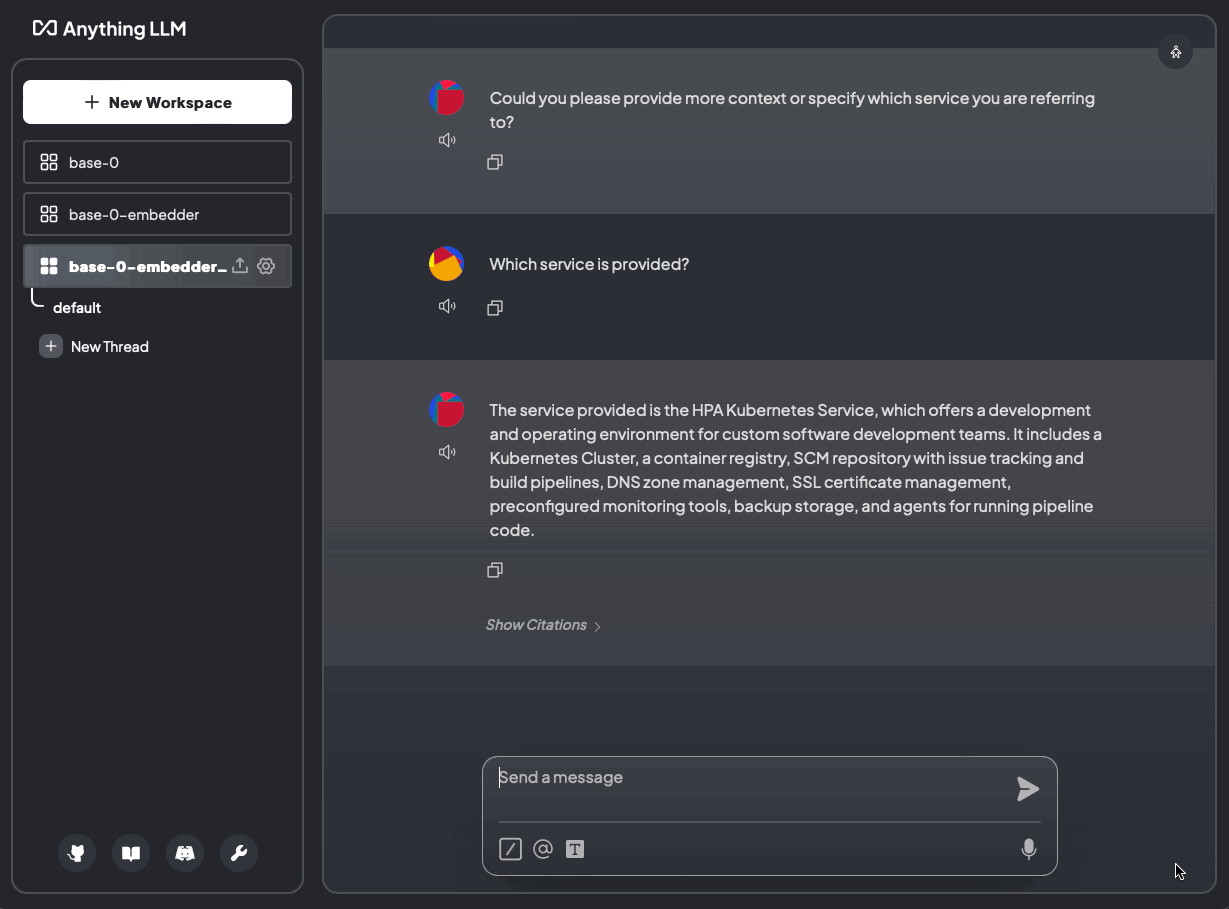
Abb. 9: Welcher Service wird angeboten? Ohne Dokumente und mit Dokumenten (base-0-embedder-vdb)
Im nächsten Teil werden wir untersuchen, wie Azure OpenAI anstelle von OpenAI verwendet werden kann. OpenAI diente nur als Beispiel, ist jedoch aufgrund von Compliance- und Datenresidenzanforderungen nicht geeignet.
AnythingLLM native Komponenten mit Azure OpenAI LLM -> base-1
Ist Azure OpenAI nicht auf OpenAI basiert und würden daher ähnliche Probleme bestehen?
Ja, Azure OpenAI verwendet die Modelle von OpenAI, bietet jedoch GDPR-Konformität, Datenresidenzoptionen und verbesserte Sicherheit, was es für Unternehmen mit strengen Datenschutzanforderungen geeigneter macht.

Bild 10: AnythingLLM native Komponenten mit Azure OpenAI LLM -> base-1
Daher müssen wir die values.yaml wie folgt anpassen:
chromadb:
enabled: true
chromadb:
auth:
enabled: false
service:
type: ClusterIP
# -- Override the full name of the chart.
fullnameOverride: "anything-llm-hks"
# -- Ingress configuration.
ingress:
# -- Enable ingress.
enabled: true
# -- Ingress annotations.
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-dns
cert-manager.io/renew-before: 360h
# -- Ingress hosts.
hosts:
- host: llm-hks.example.com
paths:
- path: /
pathType: Prefix
# -- TLS configuration for ingress.
tls:
- hosts:
- llm-hks.example.com
secretName: anything-llm-tls
# -- Configuration for the application.
config:
STORAGE_DIR: "/app/server/storage"
# EMBEDDING_MODEL_PREF: "nomic-embed-text:latest"
EMBEDDING_MODEL_MAX_CHUNK_LENGTH: "8192"
EMBEDDING_MODEL_PREF: "ada-002"
EMBEDDING_ENGINE: 'azure'
VECTOR_DB: "chroma"
WHISPER_PROVIDER: "local"
TTS_PROVIDER: "native"
LLM_PROVIDER: 'azure'
AZURE_OPENAI_ENDPOINT: https://xxx-interface.openai.azure.com/
# -- Secret configuration.
secret:
# -- Enable secrets.
enabled: true
# -- Name of the secret, if not set, a secret is generated.
name: ""
# -- Secret data.
data:
AUTH_TOKEN: "r6.."
JWT_SECRET: "CM..."
AZURE_OPENAI_KEY: "sk-pr..."
CHROMA_ENDPOINT: http://anything-llm-hks-chromadb:8000Wir ändern die VECTOR_DB zurück zu lancedb und setzen den LLM_PROVIDER auf azure sowie nehmen einige Anpassungen vor. Wir lassen ChromaDB weiterhin bereitgestellt, da es nicht stört.
Jetzt deployen wir es!
helm template anything-llm-hks anything-llm/anything-llm -f values.yaml | k apply -f -Nun laden wir unsere Daten hoch und stellen die Frage: „Welcher Service wird angeboten?“
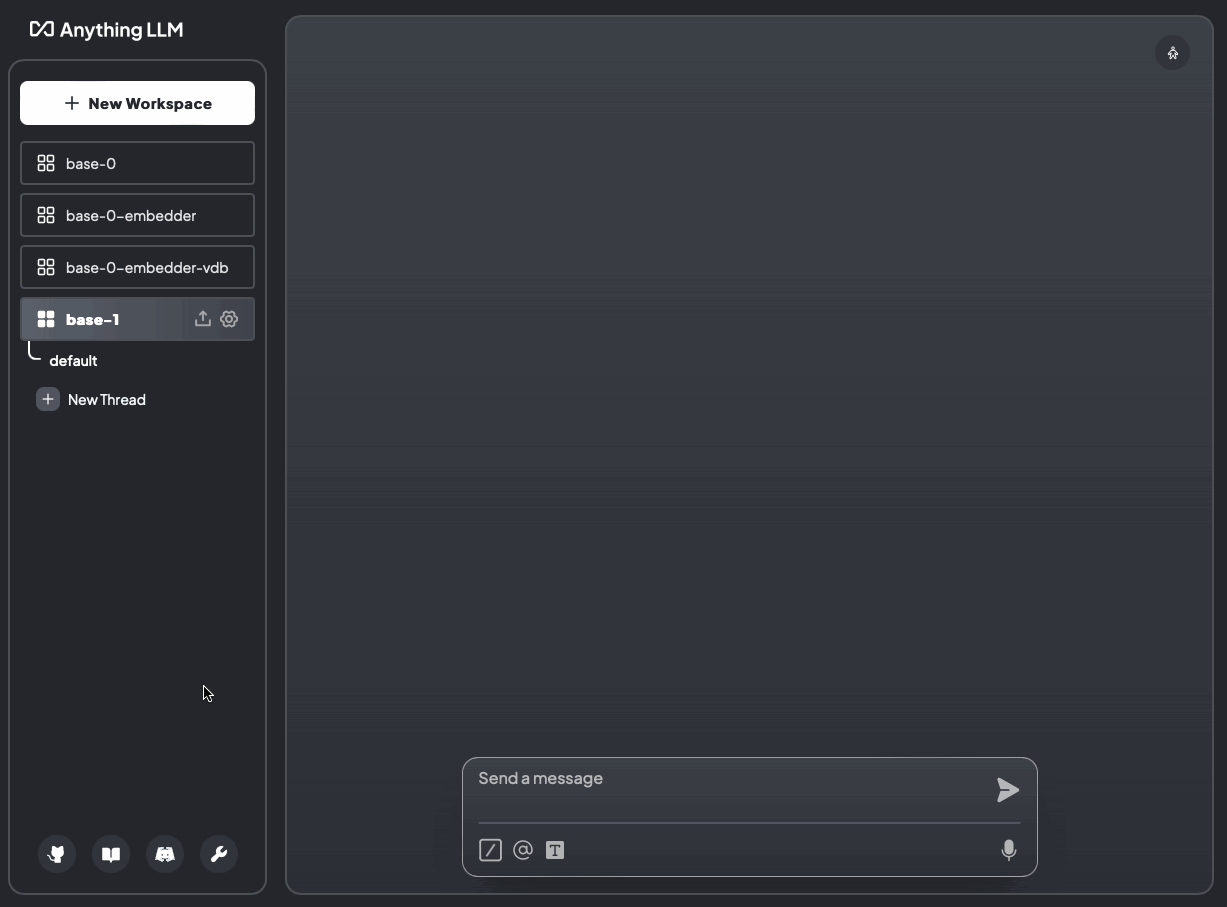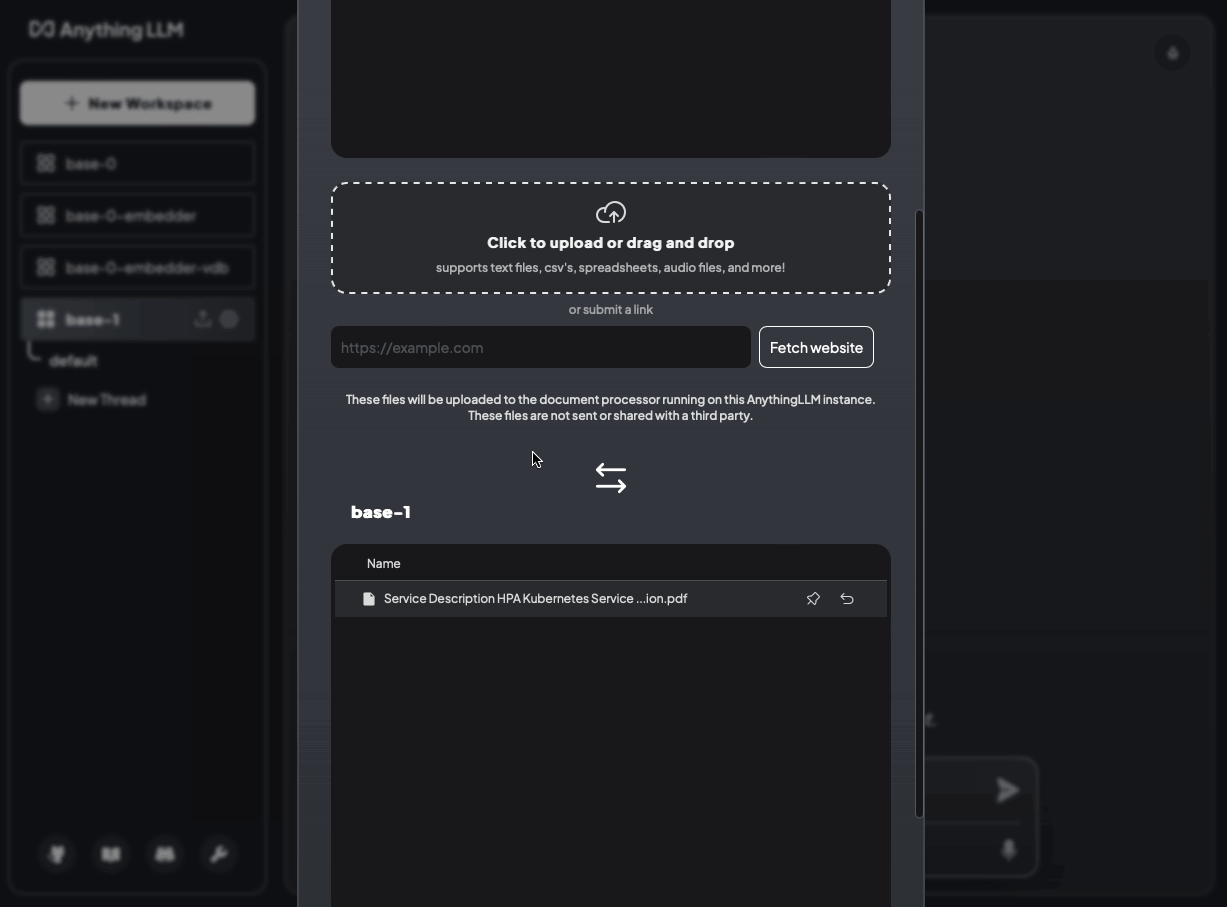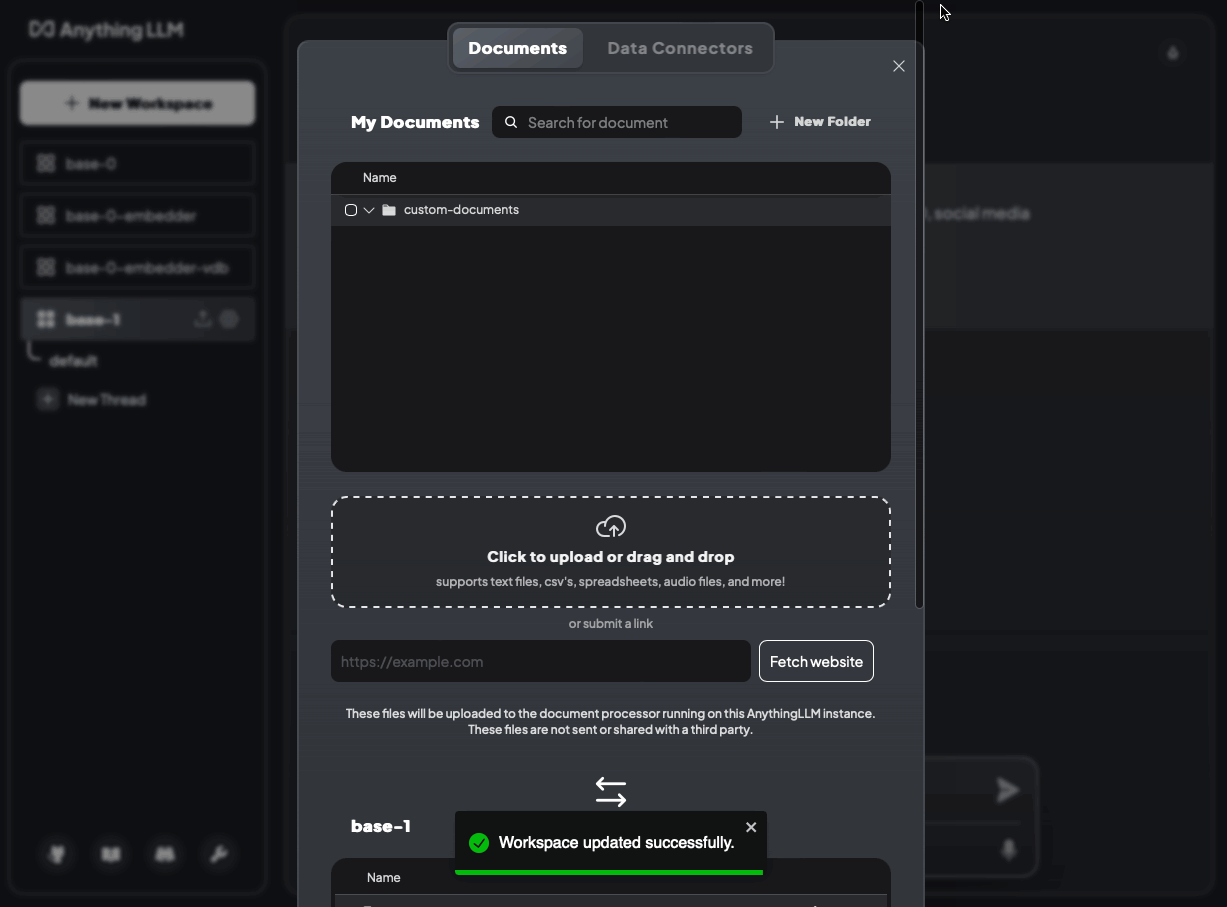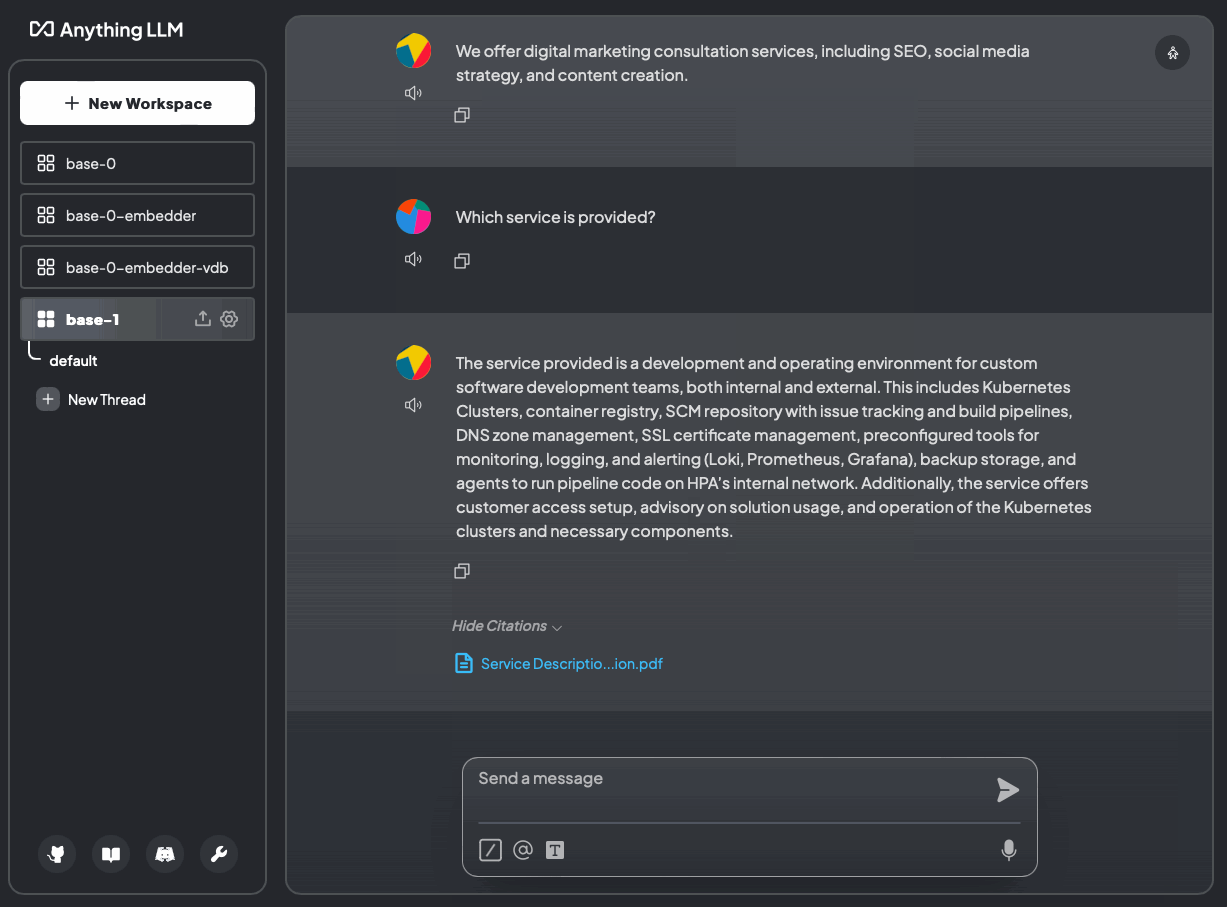
Bild 11: Welcher Service wird angeboten? Ohne Dokumente und mit Dokumenten (base-1)
Im nächsten Abschnitt verwenden wir den ada02-Embedder anstelle des nomic-Embedders.
AnythingLLM native Komponenten mit Azure OpenAI LLM und Azure OpenAI Embedder (text-embedding-ada-02) -> base-1-embedder
Wir werden den nativen Anything-LLM (nomic-embed-text) Embedder durch den Azure OpenAI text-embedding-ada-002 Embedder ersetzen.

Abb. 12: AnythingLLM native Komponenten mit Azure OpenAI LLM -> base-1-embedder
Wir müssen die values.yaml wie folgt modifizieren:
chromadb:
enabled: true
chromadb:
auth:
enabled: false
service:
type: ClusterIP
# -- Override the full name of the chart.
fullnameOverride: "anything-llm-hks"
# -- Ingress configuration.
ingress:
# -- Enable ingress.
enabled: true
# -- Ingress annotations.
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-dns
cert-manager.io/renew-before: 360h
# -- Ingress hosts.
hosts:
- host: llm-hks.example.com
paths:
- path: /
pathType: Prefix
# -- TLS configuration for ingress.
tls:
- hosts:
- llm-hks.example.com
secretName: anything-llm-tls
# -- Configuration for the application.
config:
STORAGE_DIR: "/app/server/storage"
# EMBEDDING_MODEL_PREF: "nomic-embed-text:latest"
EMBEDDING_MODEL_MAX_CHUNK_LENGTH: "8192"
EMBEDDING_MODEL_PREF: "ada-002"
EMBEDDING_ENGINE: 'azure'
VECTOR_DB: "lancedb"
WHISPER_PROVIDER: "local"
TTS_PROVIDER: "native"
LLM_PROVIDER: 'azure'
AZURE_OPENAI_ENDPOINT: https://xxx-interface.openai.azure.com/
# -- Secret configuration.
secret:
# -- Enable secrets.
enabled: true
# -- Name of the secret, if not set, a secret is generated.
name: ""
# -- Secret data.
data:
AUTH_TOKEN: "r6.."
JWT_SECRET: "CM..."
AZURE_OPENAI_KEY: "sk-pr..."
CHROMA_ENDPOINT: http://anything-llm-hks-chromadb:8000
Wir ändern VECTOR_DB zurück auf lancedb, setzen LLM_PROVIDER auf azure und passen einige weitere Einstellungen an. Außerdem muss EMBEDDING_ENGINE auf 'azure' gesetzt werden, anstatt auf openai. Achtung! EMBEDDING_MODEL_PREF: "ada-002" ist nicht der Modellname in Azure, sondern der von Ihnen vergebene Bereitstellungsname! In unserem Fall ist es ada-002.
Nun lasst uns die Bereitstellung durchführen:
helm template anything-llm-hks anything-llm/anything-llm -f values.yaml | k apply -f -Laden wir nun unsere Daten hoch und fragen: “Welcher Service wird angeboten?”
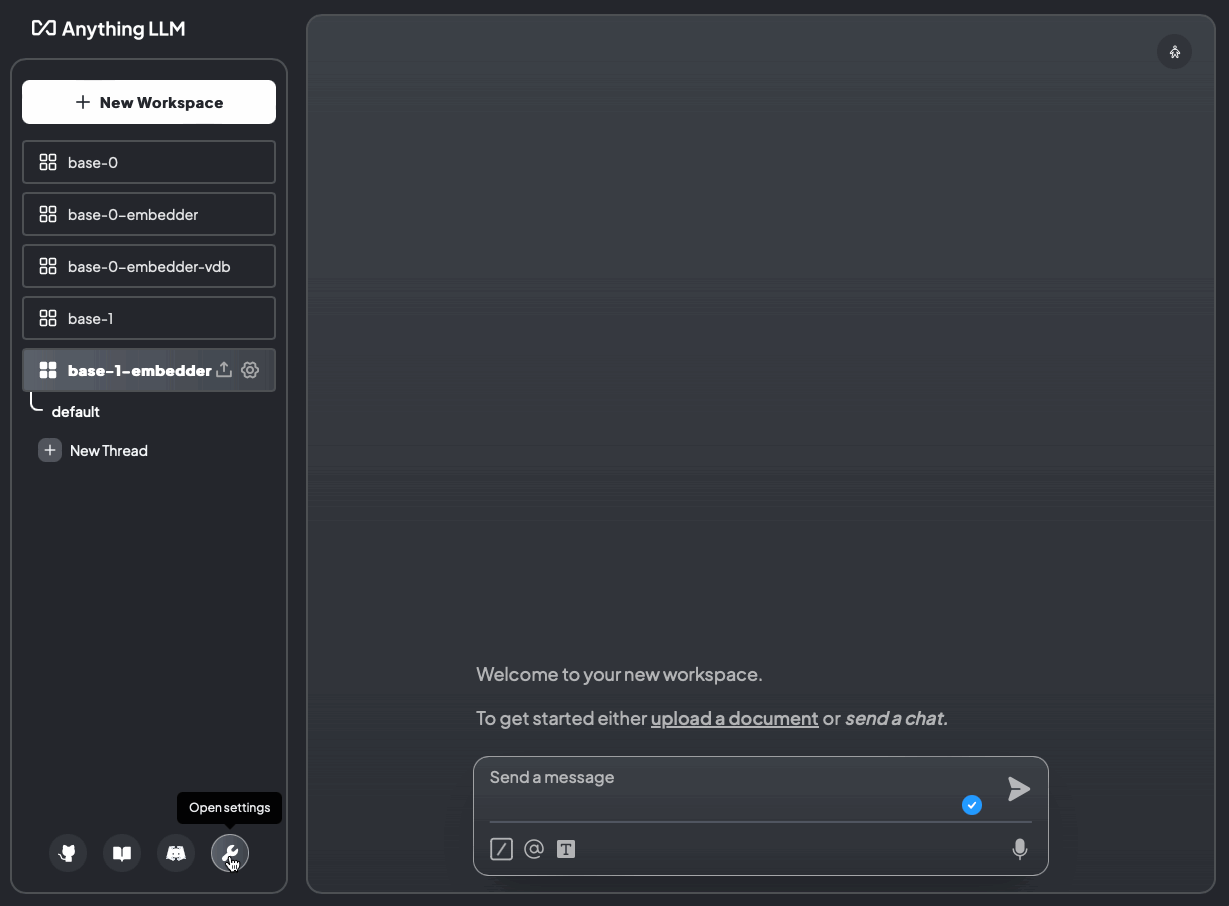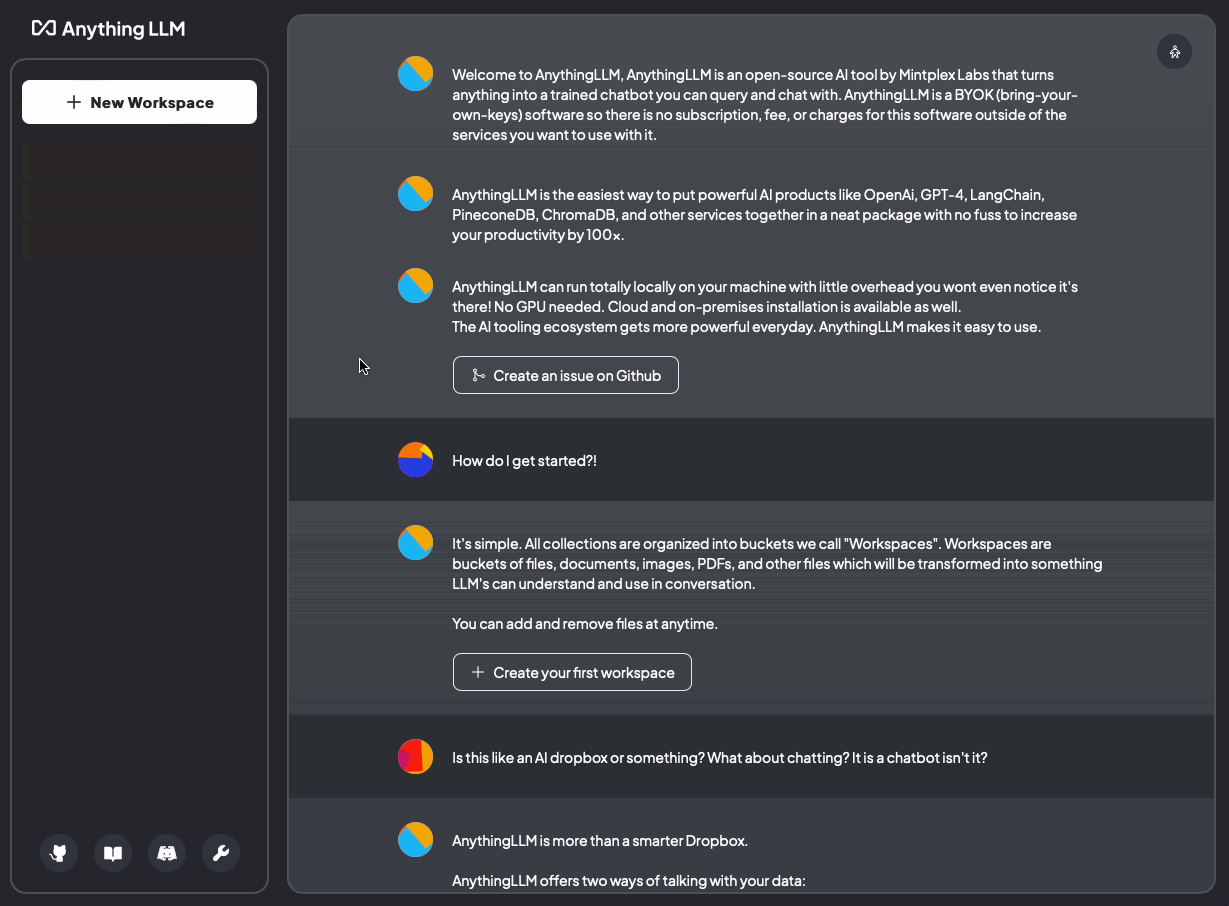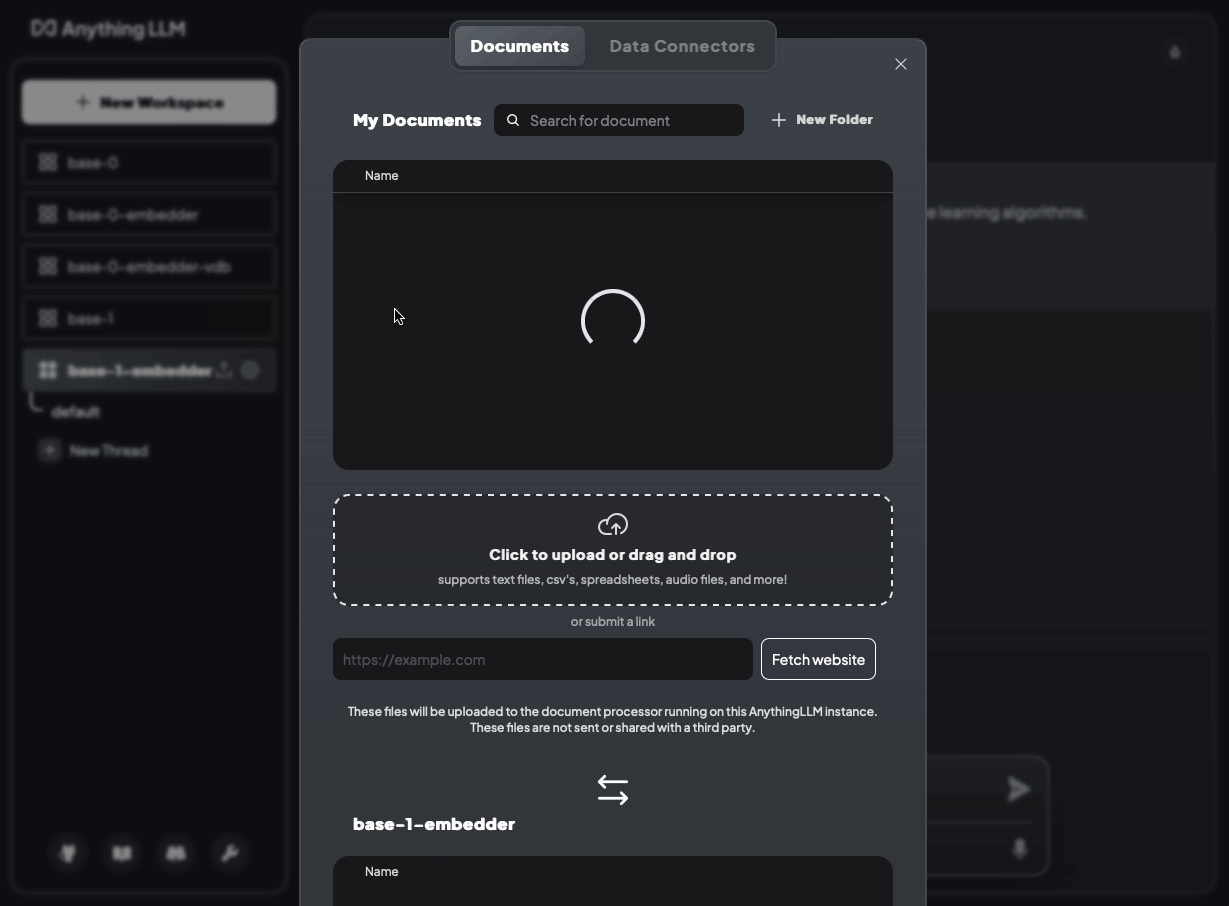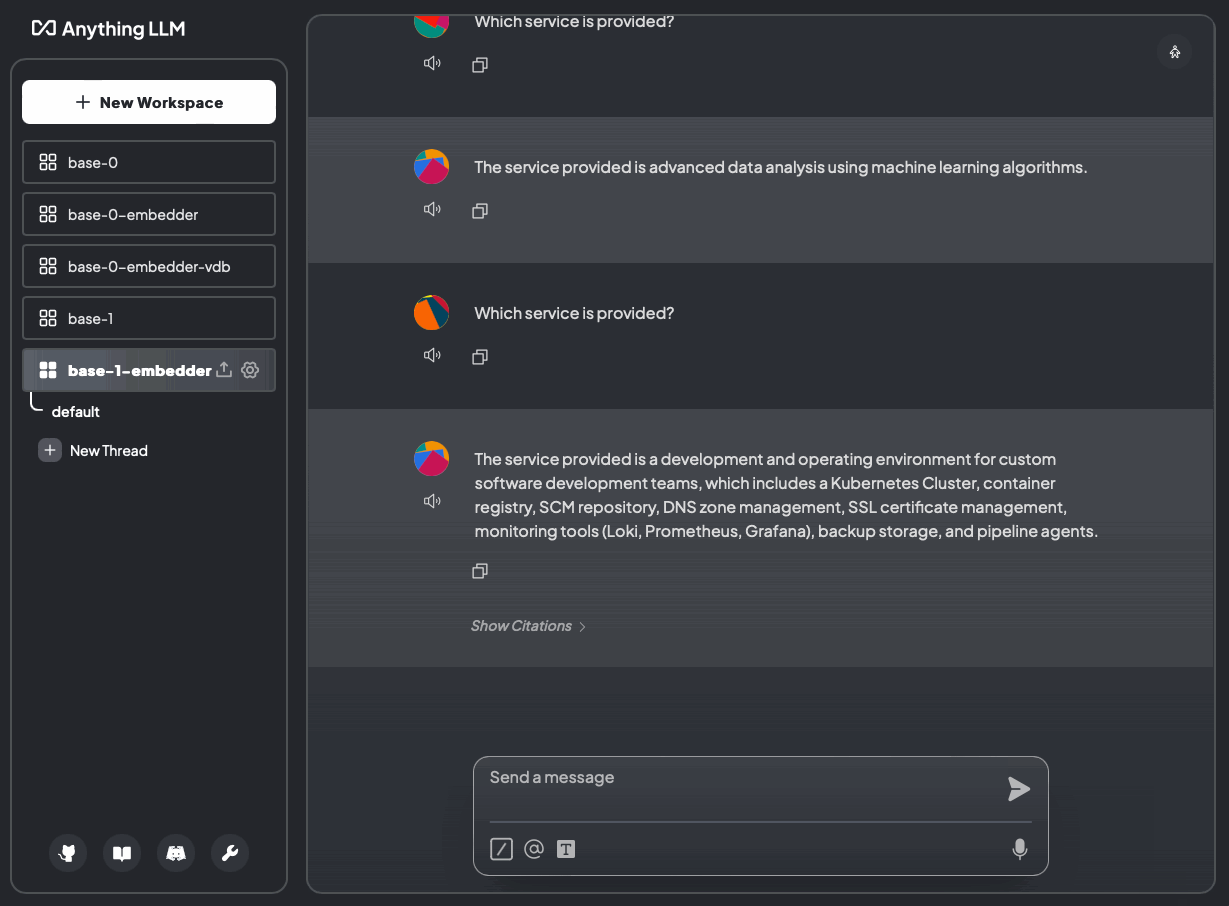
Bild 13: Welcher Service wird angeboten? Ohne Dokumente und mit Dokumenten (base-1-embedder)
Ähnlich wie der OpenAI-Embedder, auch mit derselben Zitierübereinstimmung von 77%.
Im nächsten Abschnitt verwenden wir erneut ChromaDB als Vektordatenbank.
AnythingLLM mit Azure OpenAI LLM und OpenAI Embedder (text-embedding-ada-02) und ChromaDB (Vektordatenbank) -> base-1-embedder-vdb
Wir ersetzen den nativen Anything-LLM-Embedder (nomic-embed-text) mit Azure OpenAI text-embedding-ada-002 und die LanceDB mit ChromaDB.
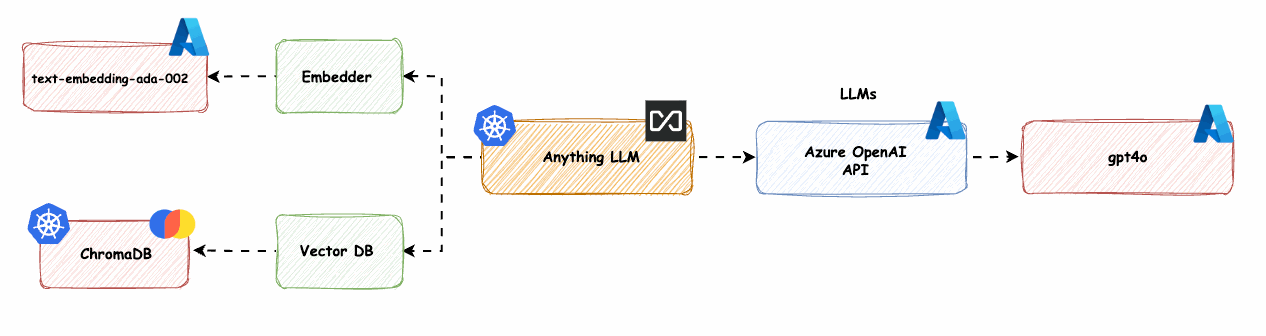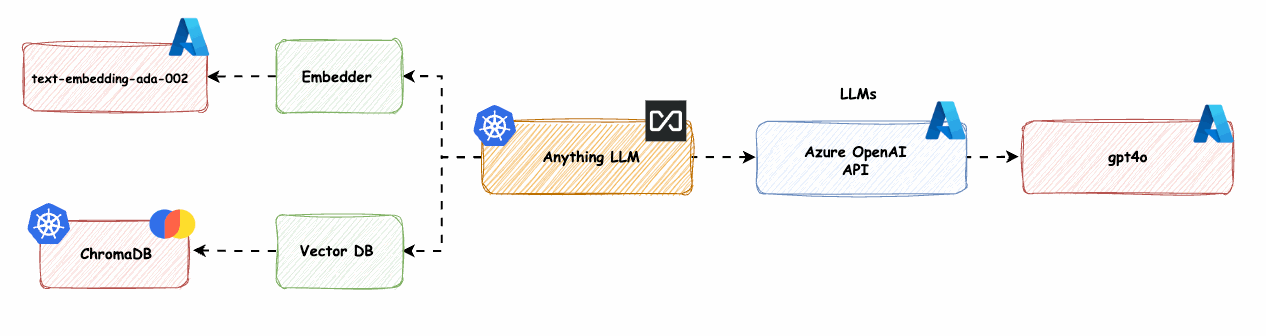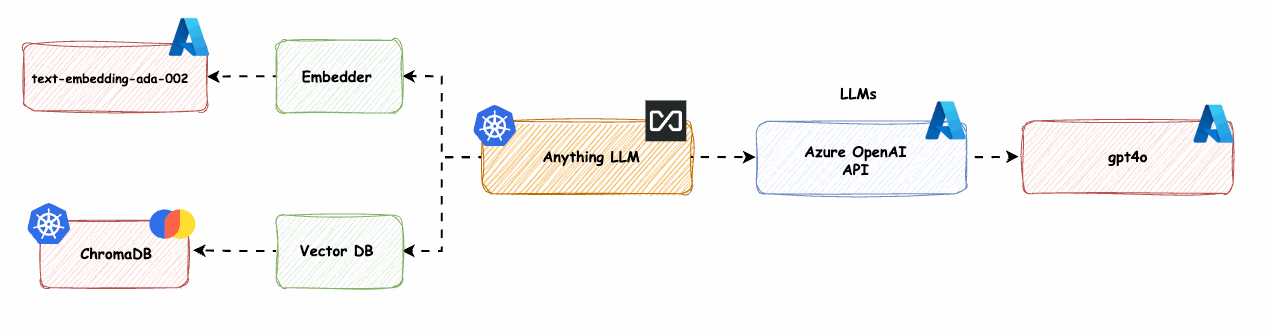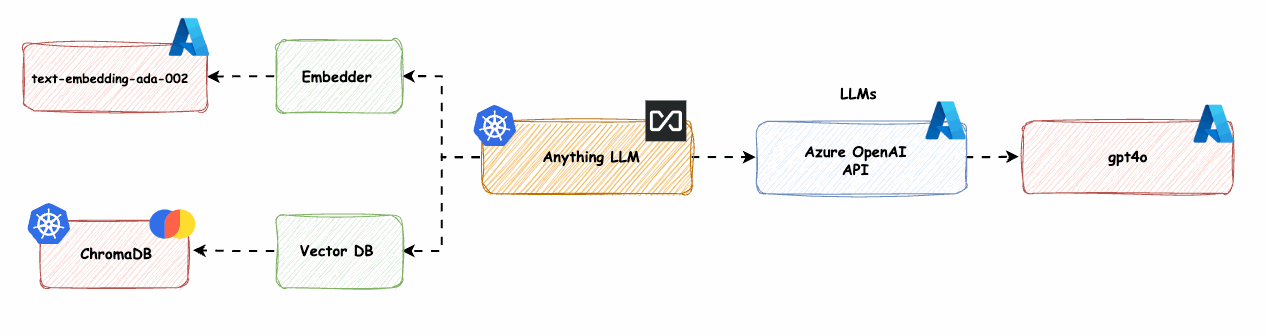
Bild 14: AnythingLLM native Komponenten mit Azure OpenAI LLM -> base-1-embedder-vdb
Wir müssen die values.yaml wie folgt anpassen:
chromadb:
enabled: true
chromadb:
auth:
enabled: false
service:
type: ClusterIP
# -- Override the full name of the chart.
fullnameOverride: "anything-llm-hks"
# -- Ingress configuration.
ingress:
# -- Enable ingress.
enabled: true
# -- Ingress annotations.
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-dns
cert-manager.io/renew-before: 360h
# -- Ingress hosts.
hosts:
- host: llm-hks.example.com
paths:
- path: /
pathType: Prefix
# -- TLS configuration for ingress.
tls:
- hosts:
- llm-hks.example.com
secretName: anything-llm-tls
# -- Configuration for the application.
config:
STORAGE_DIR: "/app/server/storage"
# EMBEDDING_MODEL_PREF: "nomic-embed-text:latest"
EMBEDDING_MODEL_MAX_CHUNK_LENGTH: "8192"
EMBEDDING_MODEL_PREF: "ada-002"
EMBEDDING_ENGINE: 'azure'
VECTOR_DB: "chroma"
WHISPER_PROVIDER: "local"
TTS_PROVIDER: "native"
LLM_PROVIDER: 'azure'
AZURE_OPENAI_ENDPOINT: https://xxx-interface.openai.azure.com/
# -- Secret configuration.
secret:
# -- Enable secrets.
enabled: true
# -- Name of the secret, if not set, a secret is generated.
name: ""
# -- Secret data.
data:
AUTH_TOKEN: "r6.."
JWT_SECRET: "CM..."
AZURE_OPENAI_KEY: "sk-pr..."
CHROMA_ENDPOINT: http://anything-llm-hks-chromadb:8000Wir müssen nur die VECTOR_DB auf chroma ändern.
Jetzt lassen Sie uns die Bereitstellung durchführen:
helm template anything-llm-hks anything-llm/anything-llm -f values.yaml | k apply -f -Laden wir nun unsere Daten hoch und fragen: “Welcher Service wird angeboten?”
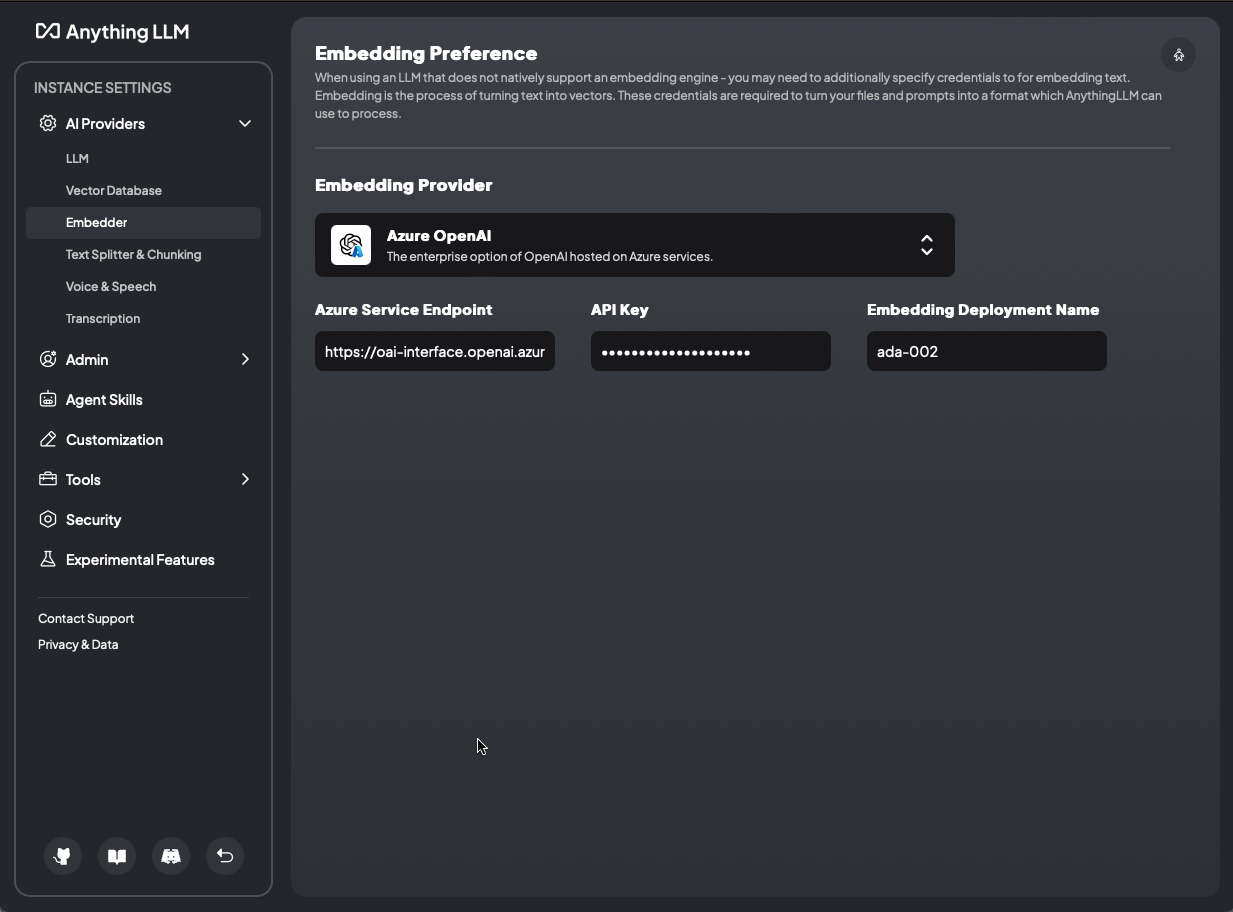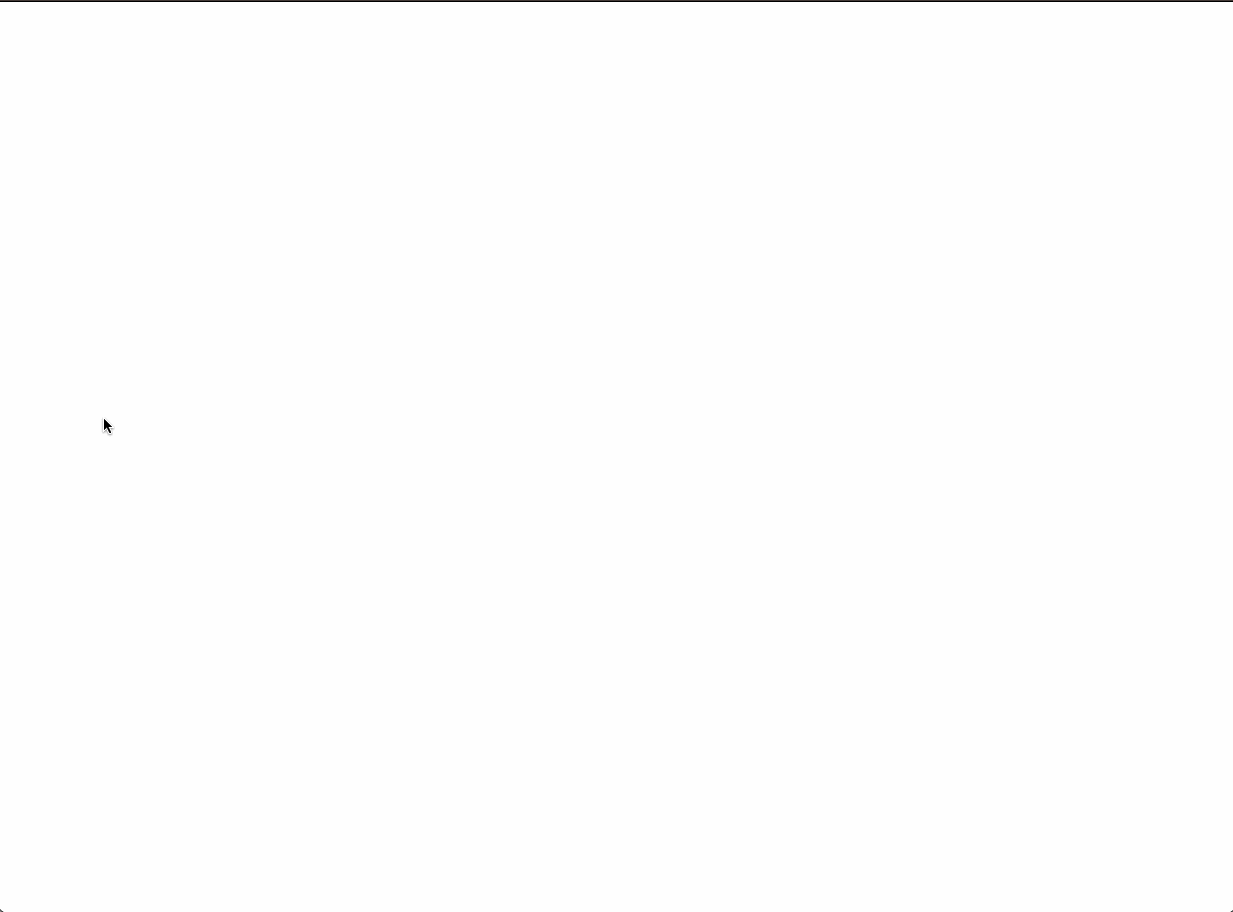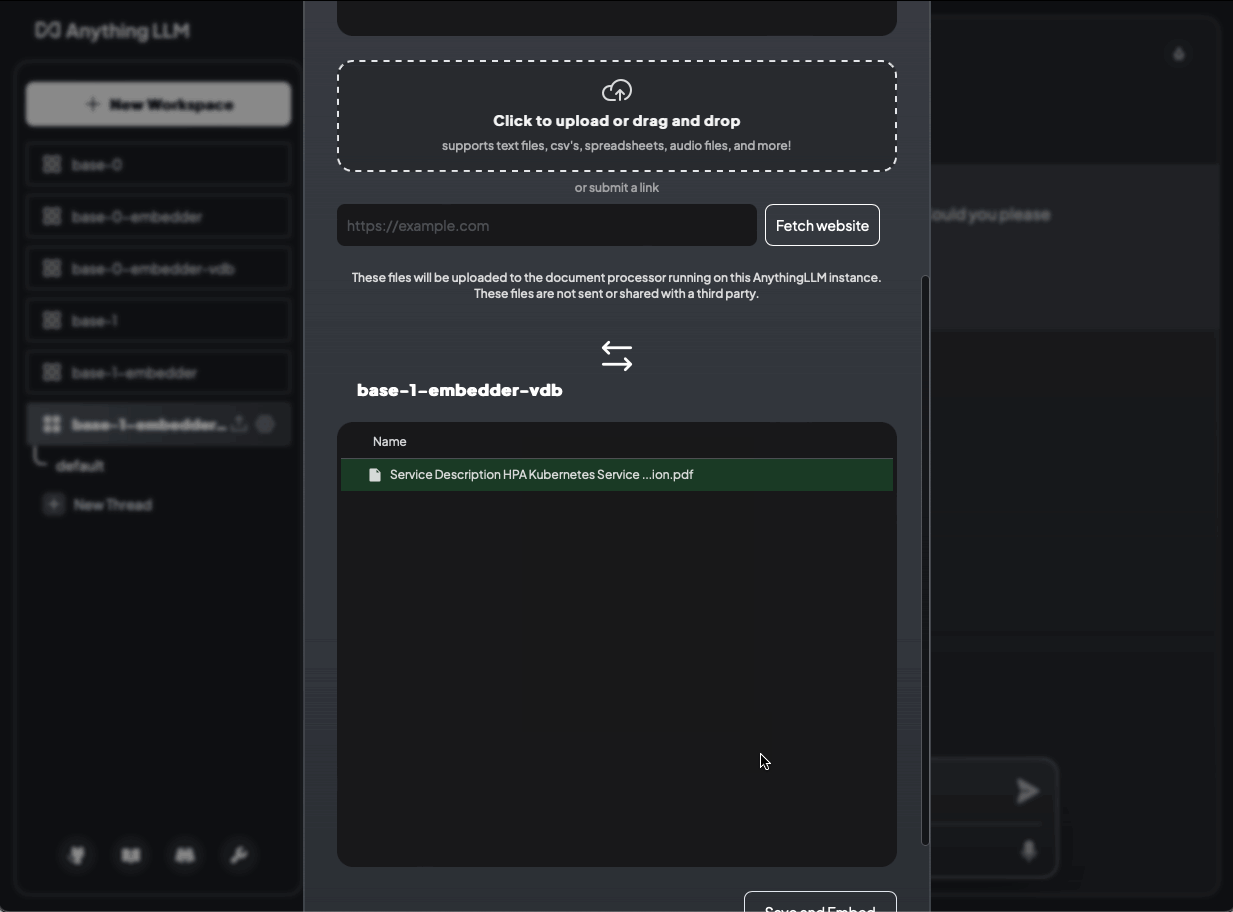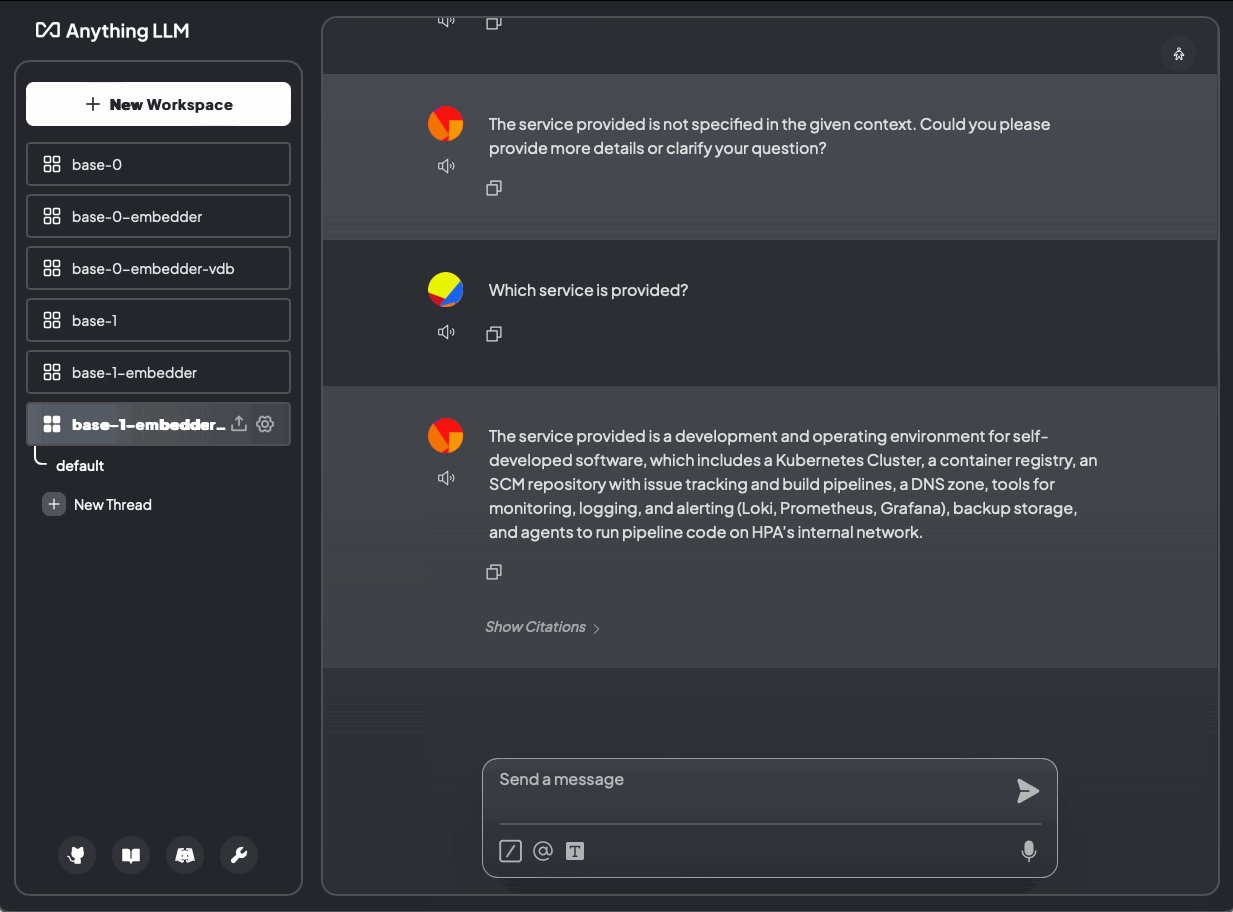
Bild 15: Welcher Service wird angeboten? Ohne Dokumente und mit Dokumenten (base-1-embedder-vdb)
Die Konfiguration sieht ähnlich aus wie bei OpenAI (base-0-embedder-vdb). Bei Verwendung von ChromaDB gibt es jedoch keine prozentuale Übereinstimmung mehr. Es ist unklar, ob dies auf ChromaDB, die Version oder die Bereitstellungskonfiguration zurückzuführen ist.
Der nächste Teil wird spannend, da wir nicht nur Ollama auf Kubernetes bereitstellen, sondern auch ein NVIDIA-Plugin installieren, um GPU-Workloads im GPU-Knotenpool zu ermöglichen.
AnythingLLM native Komponenten mit Ollama LLM -> base-2
Hinweis: Dies ist der spannendste Teil, bei dem alles auf Ihrer eigenen Infrastruktur oder einer bereitgestellten Infrastruktur läuft und keine Abhängigkeit von einer externen Schnittstelle besteht.
In diesem Teil muss ein GPU-Knotenpool bereitgestellt werden. Ich werde den Knotenpool tainten, um sicherzustellen, dass keine anderen Workloads darauf zugreifen können. Anschließend werden wir das NVIDIA-Plugin bereitstellen, damit die GPU von den Workloads genutzt werden kann. Ollama wird die GPU-Architektur, insbesondere das Gemma2-Framework, für verbesserte Leistung nutzen.
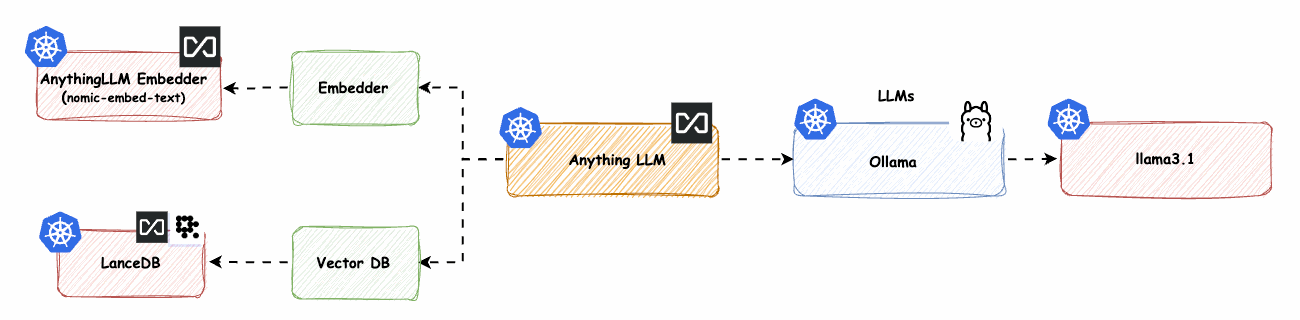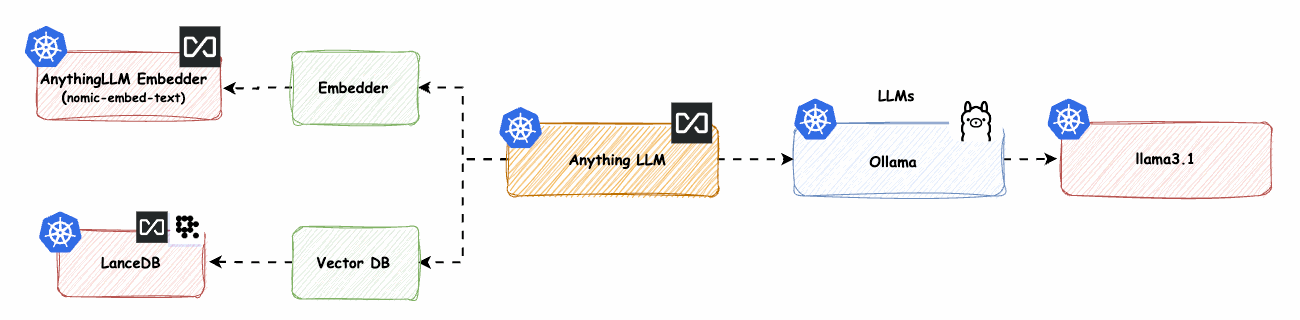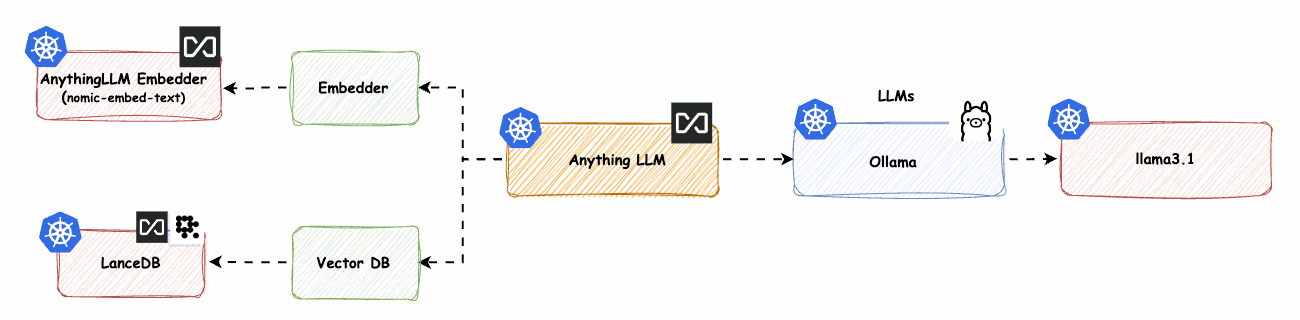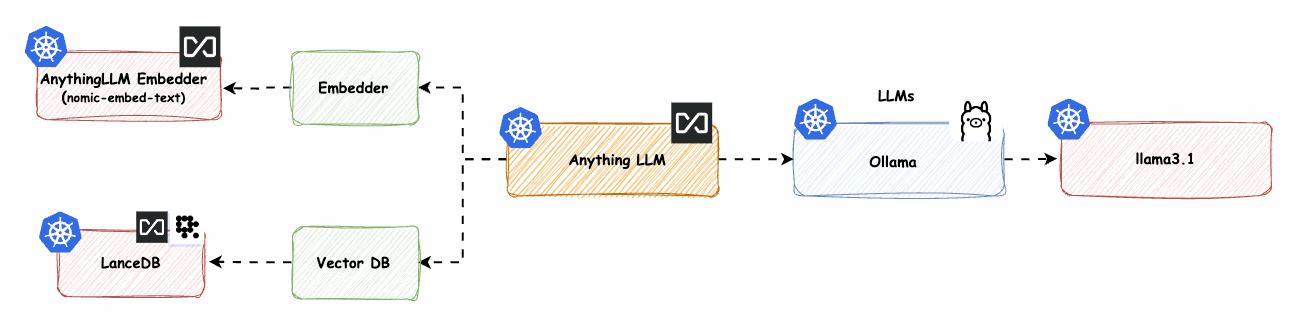
Abb. 16: AnythingLLM-native Komponenten mit Azure OpenAI LLM -> base-2
Wir müssen die values.yaml wie folgt anpassen:
chromadb:
enabled: true
chromadb:
auth:
enabled: false
service:
type: ClusterIP
# -- Den vollständigen Namen des Charts überschreiben.
fullnameOverride: "anything-llm-hks"
# -- Ingress-Konfiguration.
ingress:
# -- Ingress aktivieren.
enabled: true
# -- Ingress-Anmerkungen.
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-dns
cert-manager.io/renew-before: 360h
# -- Ingress-Hosts.
hosts:
- host: llm-hks.example.com
paths:
- path: /
pathType: Prefix
# -- TLS-Konfiguration für Ingress.
tls:
- hosts:
- llm-hks.example.com
secretName: anything-llm-tls
# -- Konfiguration für die Anwendung.
config:
STORAGE_DIR: "/app/server/storage"
EMBEDDING_MODEL_PREF: "nomic-embed-text:latest"
EMBEDDING_MODEL_MAX_CHUNK_LENGTH: "8192"
VECTOR_DB: "lancedb"
WHISPER_PROVIDER: "local"
TTS_PROVIDER: "native"
LLM_PROVIDER: 'ollama'
OLLAMA_BASE_PATH: 'http://anything-llm-hks-ollama:11434'
OLLAMA_MODEL_PREF: 'llama3.1'
OLLAMA_MODEL_TOKEN_LIMIT: 8192
# -- Geheimniskonfiguration.
secret:
# -- Geheimnisse aktivieren.
enabled: true
# -- Name des Geheimnisses, wenn nicht gesetzt, wird ein Geheimnis generiert.
name: ""
# -- Geheimnisdaten.
data:
AUTH_TOKEN: "r6.."
JWT_SECRET: "CM..."
OPEN_AI_KEY: "sk-pr..."
CHROMA_ENDPOINT: http://anything-llm-hks-chromadb:8000
###### OLLAMA ######
ollama:
enabled: true
fullnameOverride: "anything-llm-hks-ollama"
ollama:
gpu:
enabled: true
type: "nvidia"
number: 1
models:
- gemma2
- llama3.1
- nomic-embed-text
tolerations:
- key: "ai"
operator: "Equal"
value: "true"
effect: "NoSchedule"
persistentVolume:
enabled: true
accessModes:
- ReadWriteOnce
size: 50Gi
storageClass: ""
autoscaling:
enabled: false
maxReplicas: 1
image:
repository: ollama/ollama
tag: 0.1.48
###### NVIDIA DEVICE PLUGIN ######
nvidia-device-plugin:
enabled: true
fullnameOverride: "anything-llm-hks-nvidia-device-plugin"
resources:
limits:
nvidia.com/gpu: 1
tolerations:
- key: "ai"
operator: "Equal"
value: "true"
effect: "NoSchedule"
nodeSelector:
node.kubernetes.io/instance-type: Standard_NC6s_v3Wir müssen den LLM-Teil mit LLM_PROVIDER: ‘ollama’ konfigurieren sowie OLLAMA_BASE_PATH: 'http://anything-llm-hks-ollama:11434', OLLAMA_MODEL_PREF: ‘llama3.1’ und OLLAMA_MODEL_TOKEN_LIMIT: 8192 festlegen. Außerdem müssen wir nun ollama und nvidia-device-plugin konfigurieren.
Jetzt deployen wir es!
helm template anything-llm-hks anything-llm/anything-llm -f values.yaml | k apply -f -Laden wir unsere Daten hoch und fragen: “Welcher Service wird angeboten?”
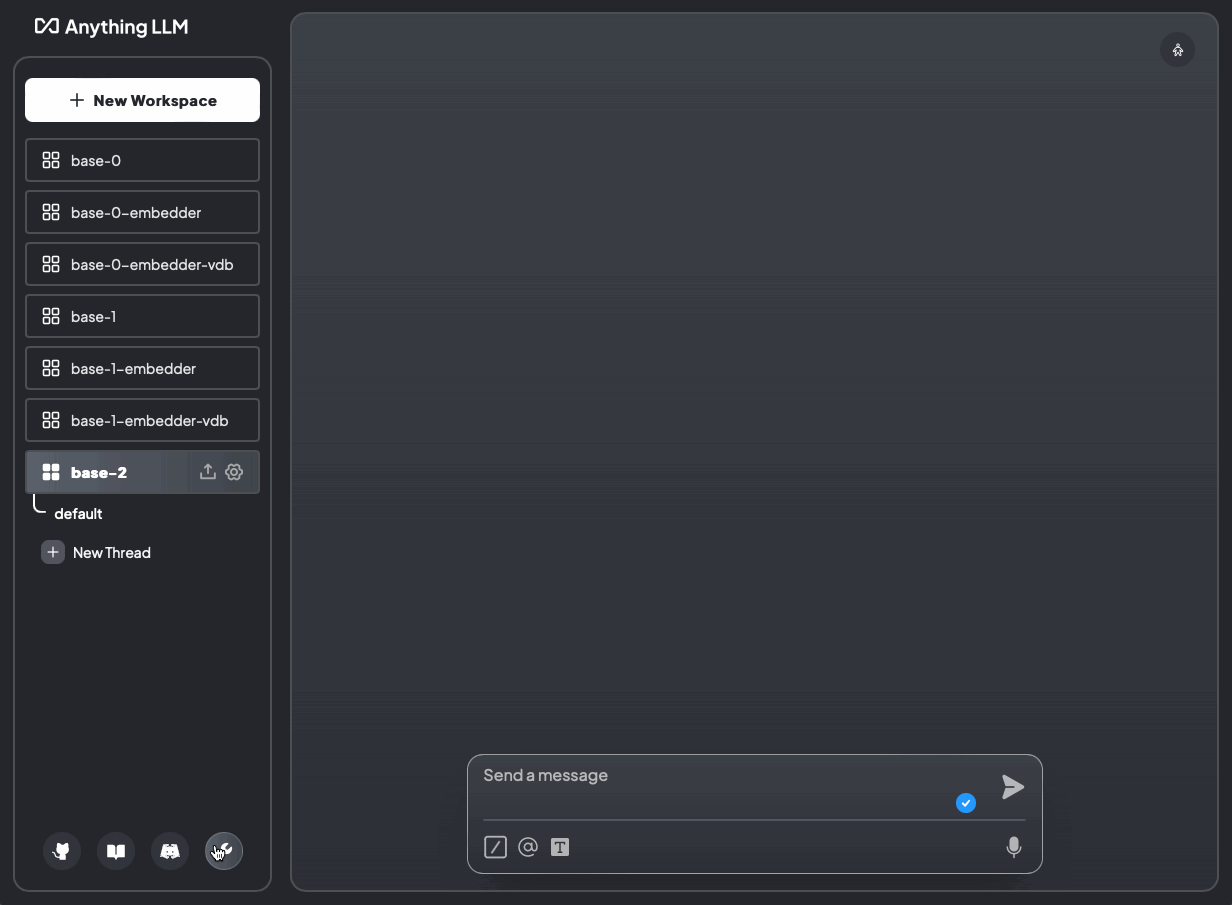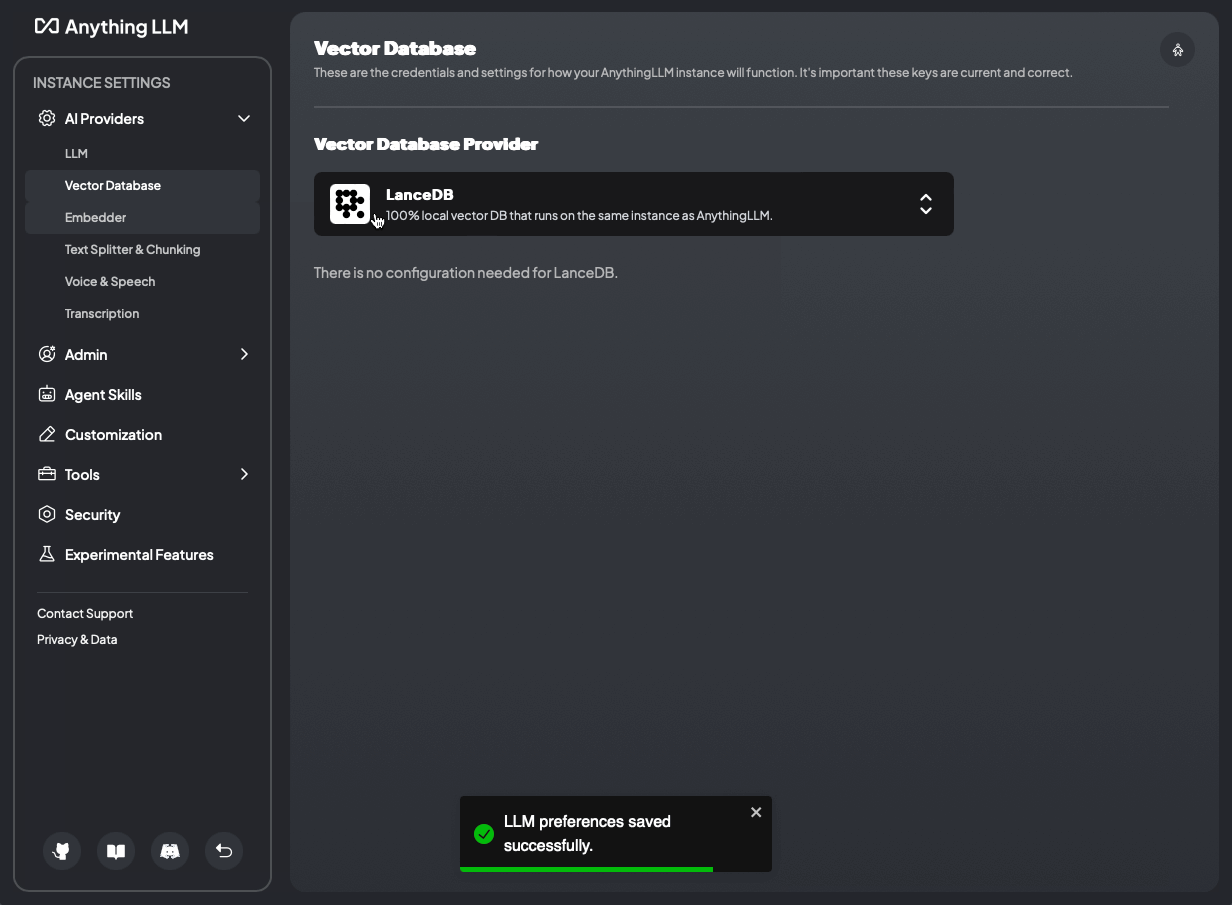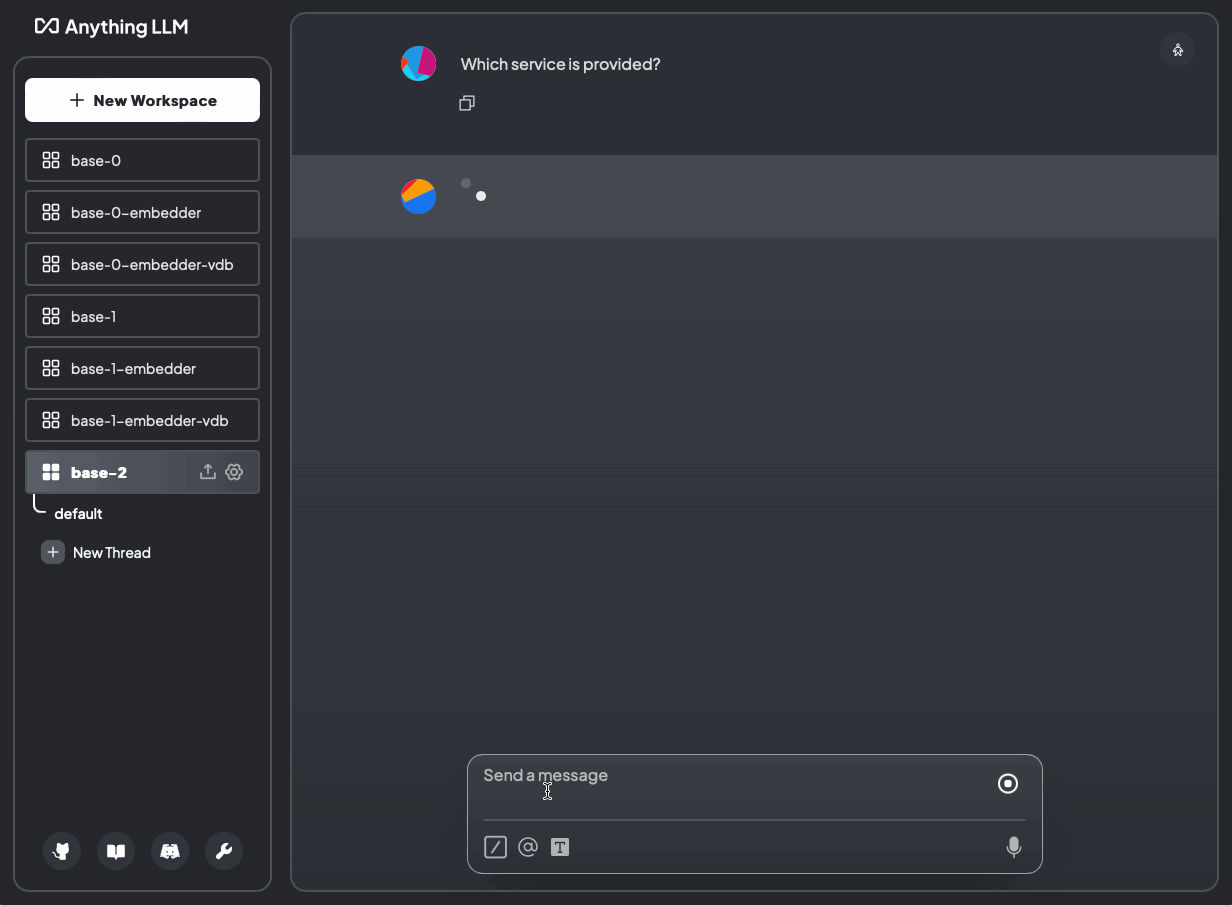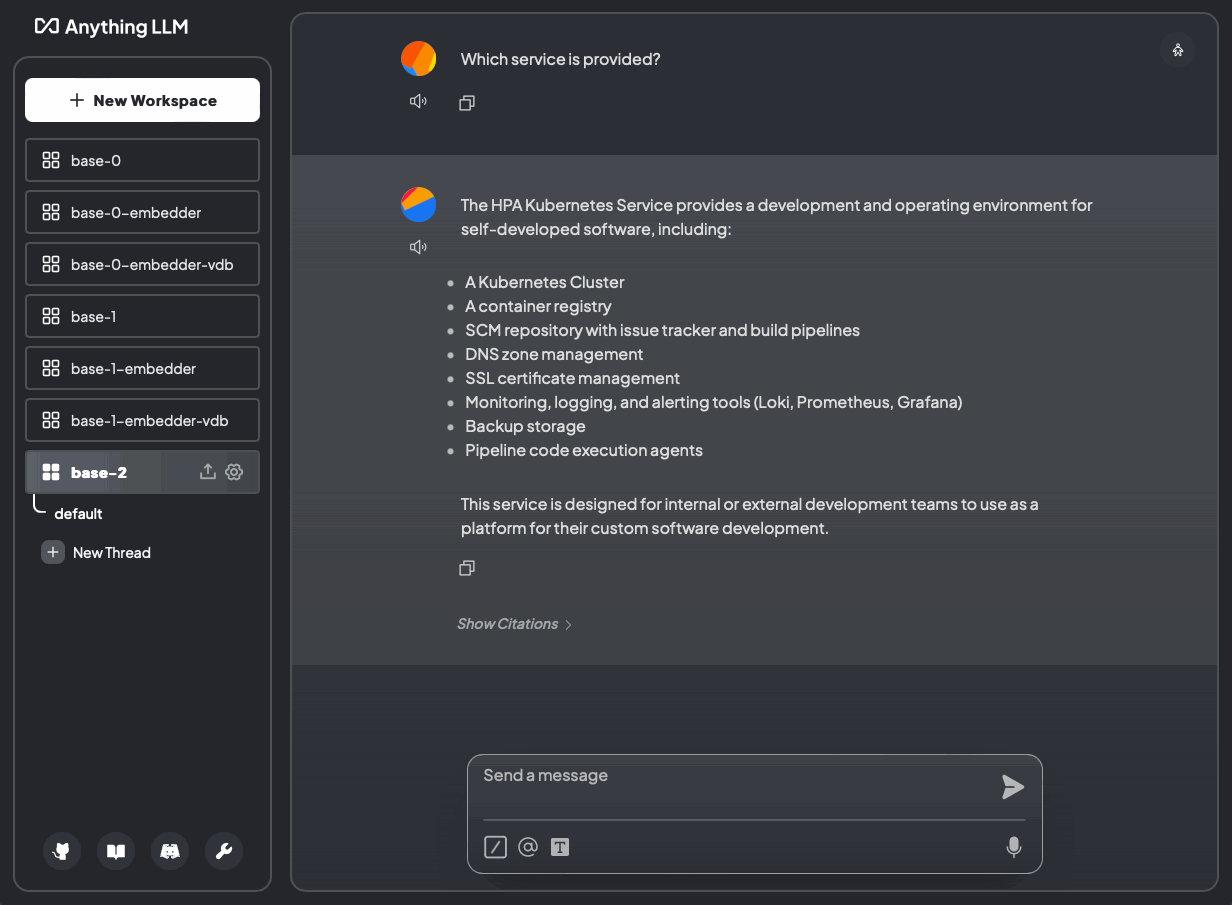
Bild 17: Welcher Service wird angeboten? Ohne Dokumente und mit Dokumenten (base-2)
Im nächsten Teil werden wir untersuchen, wie man den nomic-embed-text von anything-llm durch den nomic-embed-text von ollama ersetzt.
AnythingLLM-native Komponenten mit Ollama LLM und Ollama Embedder (nomic-embed-text) -> base-2-embedder
Wir ersetzen den nativen Anything-LLM (nomic-embed-text) Embedder mit Ollama nomic-embed-text.

Bild 18.: AnythingLLM native Komponenten mit Azure OpenAI LLM -> base-2-embedder
Wir müssen die values.yaml folgendermaßen anpassen:
chromadb:
enabled: true
chromadb:
auth:
enabled: false
service:
type: ClusterIP
# -- Override des vollständigen Namens des Charts.
fullnameOverride: "anything-llm-hks"
# -- Ingress-Konfiguration.
ingress:
enabled: true
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-dns
cert-manager.io/renew-before: 360h
hosts:
- host: llm-hks.example.com
paths:
- path: /
pathType: Prefix
tls:
- hosts:
- llm-hks.example.com
secretName: anything-llm-tls
# -- Konfiguration für die Anwendung.
config:
STORAGE_DIR: "/app/server/storage"
EMBEDDING_MODEL_PREF: "nomic-embed-text:latest"
EMBEDDING_MODEL_MAX_CHUNK_LENGTH: "8192"
EMBEDDING_BASE_PATH: "http://anything-llm-hks-ollama:11434"
EMBEDDING_ENGINE: 'ollama'
VECTOR_DB: "lancedb"
WHISPER_PROVIDER: "local"
TTS_PROVIDER: "native"
LLM_PROVIDER: 'ollama'
OLLAMA_BASE_PATH: 'http://anything-llm-hks-ollama:11434'
OLLAMA_MODEL_PREF: 'llama3.1'
OLLAMA_MODEL_TOKEN_LIMIT: 8192
# -- Geheimnis-Konfiguration.
secret:
enabled: true
name: ""
data:
AUTH_TOKEN: "r6.."
JWT_SECRET: "CM..."
OPEN_AI_KEY: "sk-pr..."
CHROMA_ENDPOINT: http://anything-llm-hks-chromadb:8000
###### OLLAMA ######
ollama:
enabled: true
fullnameOverride: "anything-llm-hks-ollama"
ollama:
gpu:
enabled: true
type: "nvidia"
number: 1
models:
- gemma2
- llama3.1
- nomic-embed-text
tolerations:
- key: "ai"
operator: "Equal"
value: "true"
effect: "NoSchedule"
persistentVolume:
enabled: true
accessModes:
- ReadWriteOnce
size: 50Gi
storageClass: ""
autoscaling:
enabled: false
maxReplicas: 1
image:
repository: ollama/ollama
tag: 0.1.48
###### NVIDIA DEVICE PLUGIN ######
nvidia-device-plugin:
enabled: true
fullnameOverride: "anything-llm-hks-nvidia-device-plugin"
resources:
limits:
nvidia.com/gpu: 1
tolerations:
- key: "ai"
operator: "Equal"
value: "true"
effect: "NoSchedule"
nodeSelector:
node.kubernetes.io/instance-type: Standard_NC6s_v3
Zusätzlich müssen wir den Embedding-Teil wie folgt konfigurieren:
EMBEDDING_MODEL_PREF: „nomic-embed-text“EMBEDDING_MODEL_MAX_CHUNK_LENGTH: „8192“EMBEDDING_BASE_PATH: „http://anything-llm-hks-ollama:11434“EMBEDDING_ENGINE: „ollama“
Nun können wir die Bereitstellung durchführen:
helm template anything-llm-hks anything-llm/anything-llm -f values.yaml | k apply -f -Laden Sie nun Ihre Daten hoch und stellen Sie die Frage: “Welcher Dienst wird bereitgestellt?
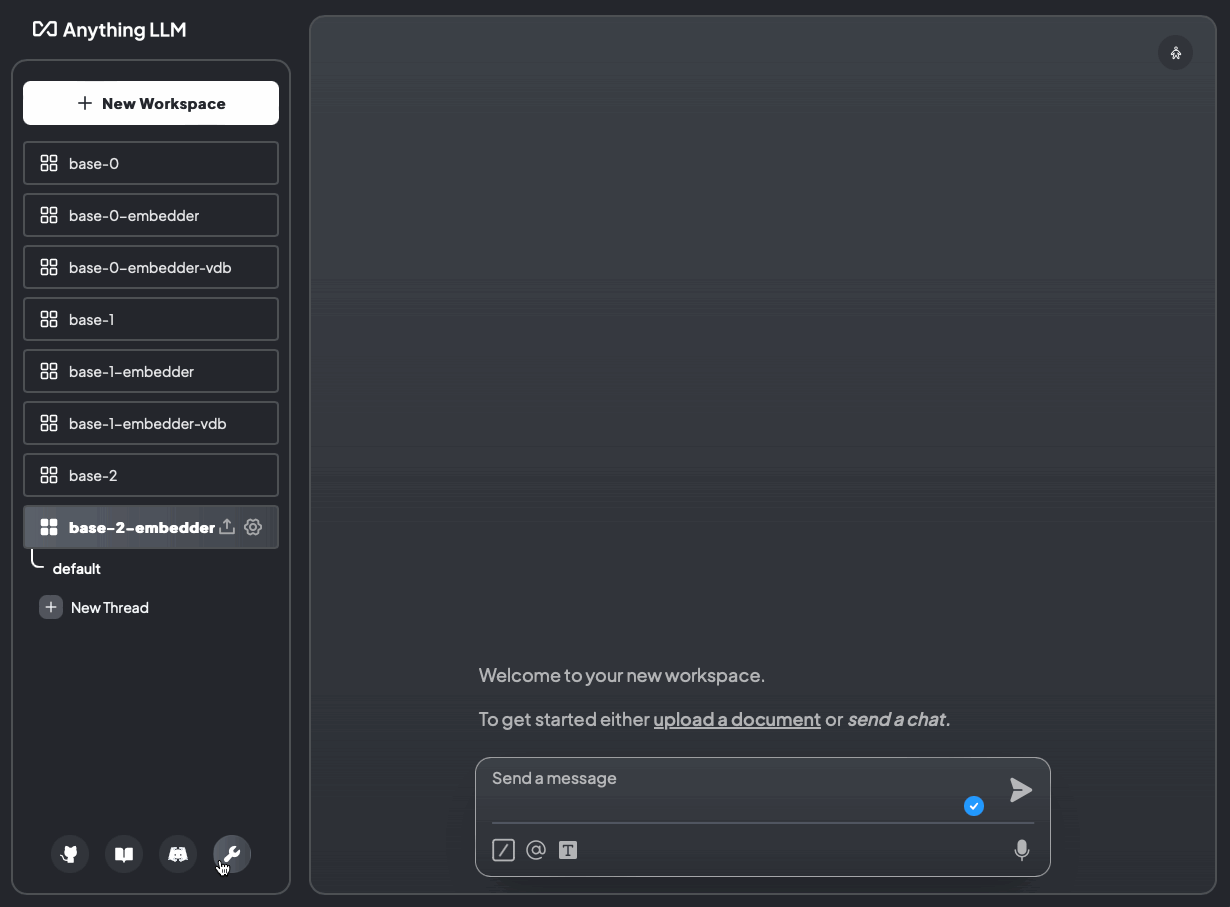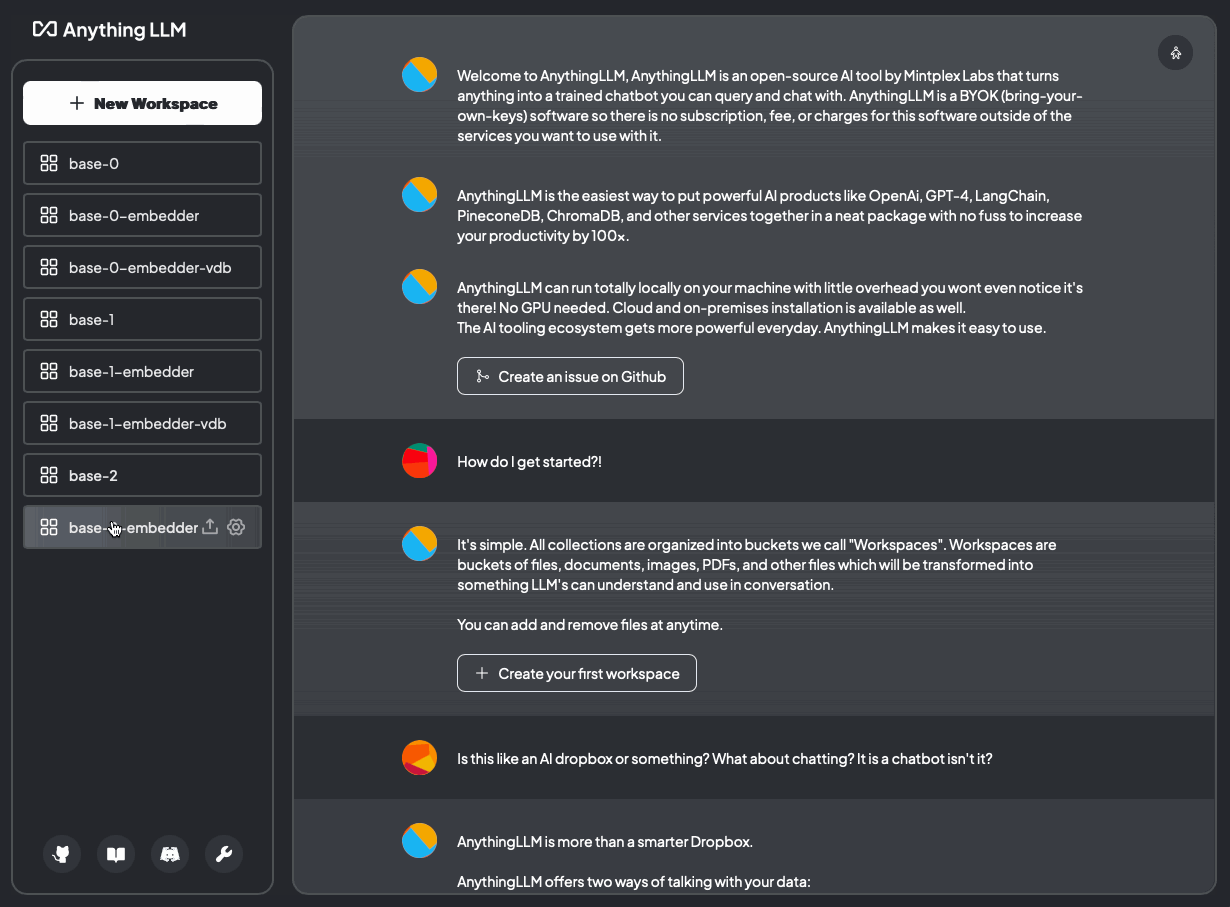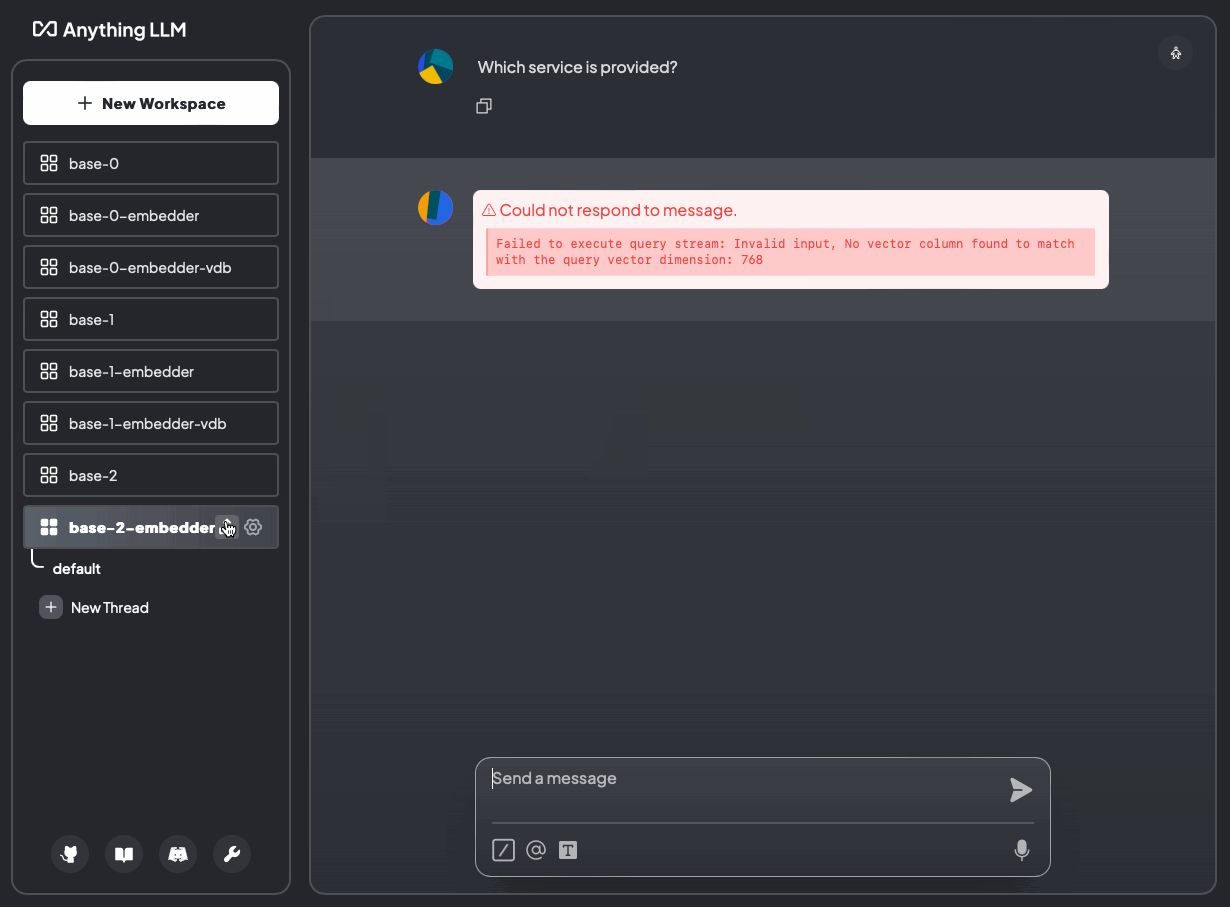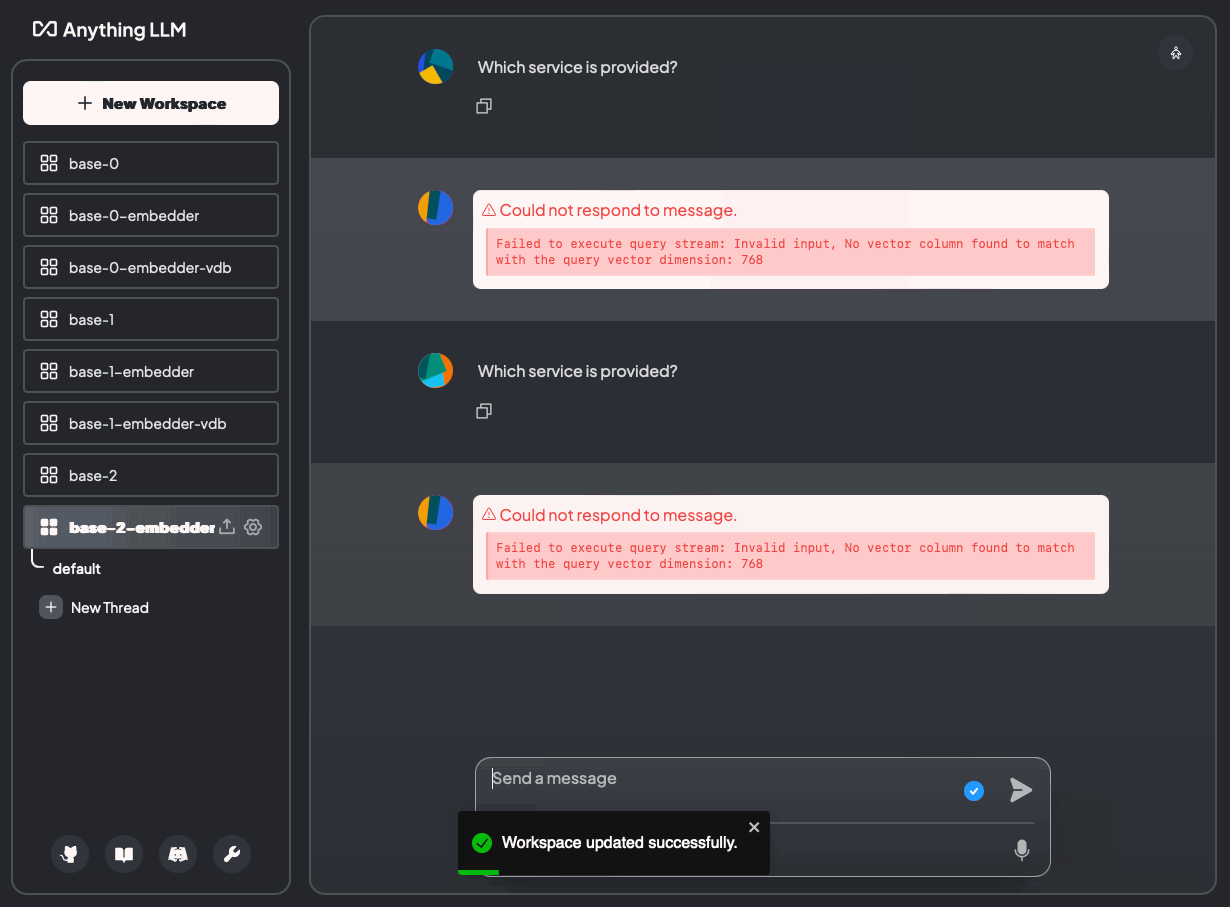
Abbildung 19: Welcher Dienst wird bereitgestellt? Ohne Dokumente und mit Dokumenten (base-2-embedder)
DIESER TEIL FEHLGESCHLAGEN! Die Fehlermeldung „Failed to execute query stream: Invalid input, No vector column found to match with the query vector dimension: 768“ deutet darauf hin, dass eine Diskrepanz zwischen der erwarteten Vektordimension und der tatsächlichen Vektordimension in Ihrer Vektordatenbank (LanceDB) vorliegt.
Im nächsten Teil werden wir die Vektordatenbank ändern und prüfen, ob dies hilft.
AnythingLLM mit Ollama LLM und Ollama Embedder (nomic-embed-text) und ChromaDB (Vektordatenbank) -> base-2-embedder-vdb
In diesem Teil tauschen wir die Vektordatenbank LanceDB gegen ChromaDB aus und prüfen, ob ChromaDB eine Spalte mit der Dimension 768 bereitstellt. Wir werden den nativen Anything-LLM (nomic-embed-text)-Embedder mit Ollama nomic-embed-text und LanceDB durch ChromaDB ersetzen.
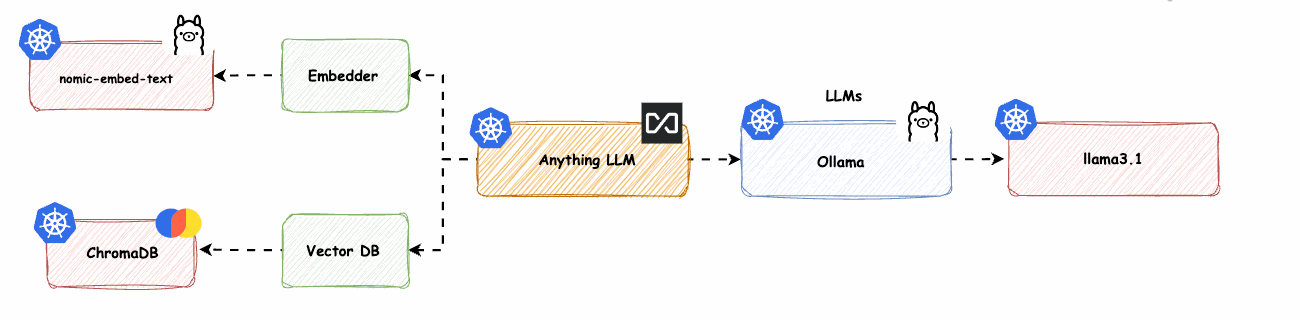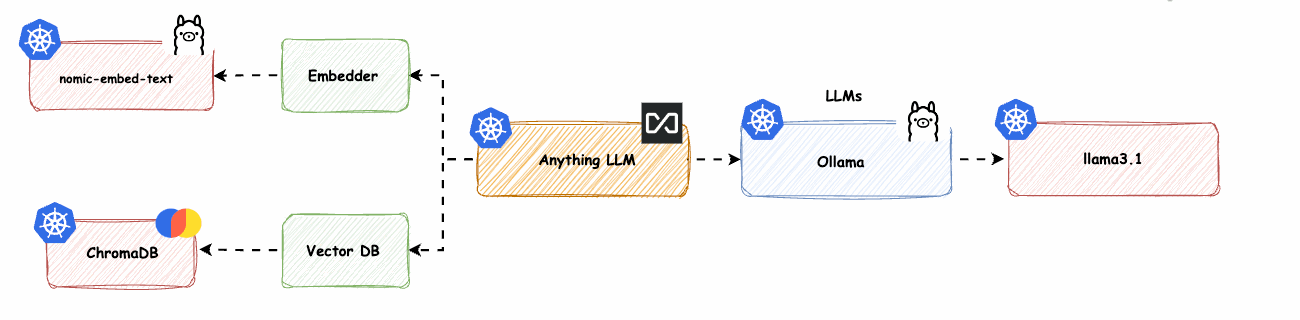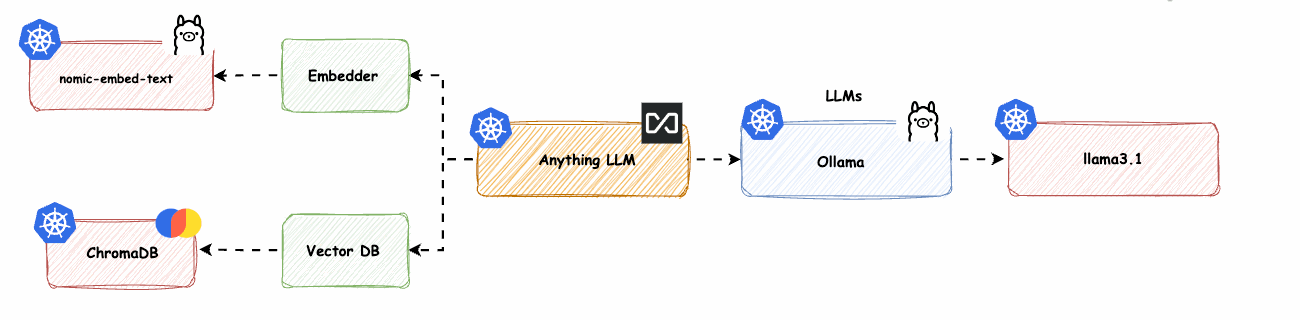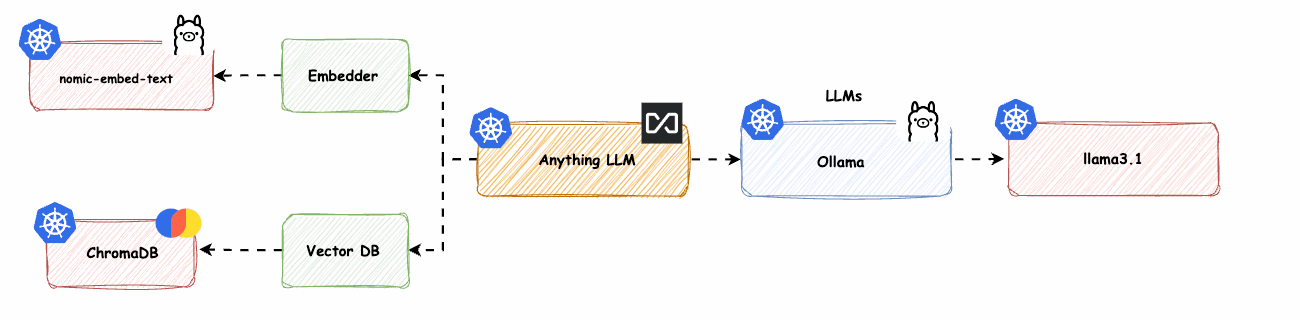
Abbildung 20: AnythingLLM mit nativen Komponenten von Azure OpenAI LLM -> base-2-embedder-vdb
helm template anything-llm-hks anything-llm/anything-llm -f values.yaml | k apply -f –
Wir müssen die Datei values.yaml wie folgt anpassen:
chromadb:
enabled: true
chromadb:
auth:
enabled: false
service:
type: ClusterIP
# -- Vollständiger Name des Charts überschreiben.
fullnameOverride: "anything-llm-hks"
# -- Ingress-Konfiguration.
ingress:
# -- Ingress aktivieren.
enabled: true
# -- Ingress-Anmerkungen.
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-dns
cert-manager.io/renew-before: 360h
# -- Ingress-Hosts.
hosts:
- host: llm-hks.example.com
paths:
- path: /
pathType: Prefix
# -- TLS-Konfiguration für Ingress.
tls:
- hosts:
- llm-hks.example.com
secretName: anything-llm-tls
# -- Konfiguration für die Anwendung.
config:
STORAGE_DIR: "/app/server/storage"
EMBEDDING_MODEL_PREF: "nomic-embed-text:latest"
EMBEDDING_MODEL_MAX_CHUNK_LENGTH: "8192"
EMBEDDING_BASE_PATH: "http://anything-llm-hks-ollama:11434"
EMBEDDING_ENGINE: 'ollama'
VECTOR_DB: "chroma"
WHISPER_PROVIDER: "local"
TTS_PROVIDER: "native"
LLM_PROVIDER: 'ollama'
OLLAMA_BASE_PATH: 'http://anything-llm-hks-ollama:11434'
OLLAMA_MODEL_PREF: 'llama3.1'
OLLAMA_MODEL_TOKEN_LIMIT: 8192
# -- Geheimnis-Konfiguration.
secret:
# -- Geheimnisse aktivieren.
enabled: true
# -- Name des Geheimnisses, falls nicht gesetzt, wird ein Geheimnis generiert.
name: ""
# -- Geheimnis-Daten.
data:
AUTH_TOKEN: "r6.."
JWT_SECRET: "CM..."
OPEN_AI_KEY: "sk-pr..."
CHROMA_ENDPOINT: http://anything-llm-hks-chromadb:8000
###### OLLAMA ######
ollama:
enabled: true
fullnameOverride: "anything-llm-hks-ollama"
ollama:
gpu:
enabled: true
type: "nvidia"
number: 1
models:
- gemma2
- llama3.1
- nomic-embed-text
tolerations:
- key: "ai"
operator: "Equal"
value: "true"
effect: "NoSchedule"
persistentVolume:
enabled: true
accessModes:
- ReadWriteOnce
size: 50Gi
storageClass: ""
autoscaling:
enabled: false
maxReplicas: 1
image:
repository: ollama/ollama
tag: 0.1.48
###### NVIDIA DEVICE PLUGIN ######
nvidia-device-plugin:
enabled: true
fullnameOverride: "anything-llm-hks-nvidia-device-plugin"
resources:
limits:
nvidia.com/gpu: 1
tolerations:
- key: "ai"
operator: "Equal"
value: "true"
effect: "NoSchedule"
nodeSelector:
node.kubernetes.io/instance-type: Standard_NC6s_v3
Die einzige Änderung, die erforderlich ist, ist das Ändern von VECTOR_DB: "chroma".
Nun lasst uns das Deployment ausführen:
helm template anything-llm-hks anything-llm/anything-llm -f values.yaml | k apply -f -Jetzt laden wir unsere Daten hoch und stellen die Frage:
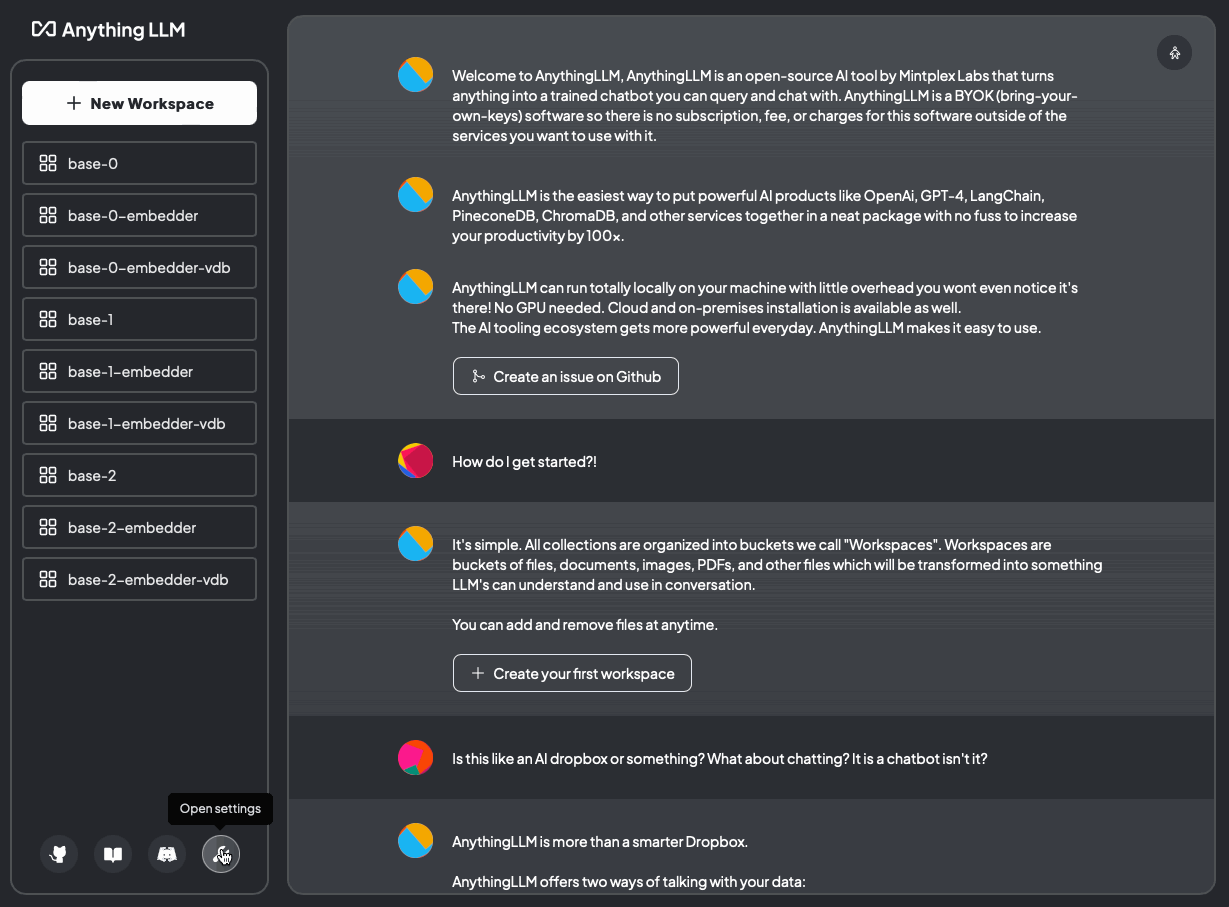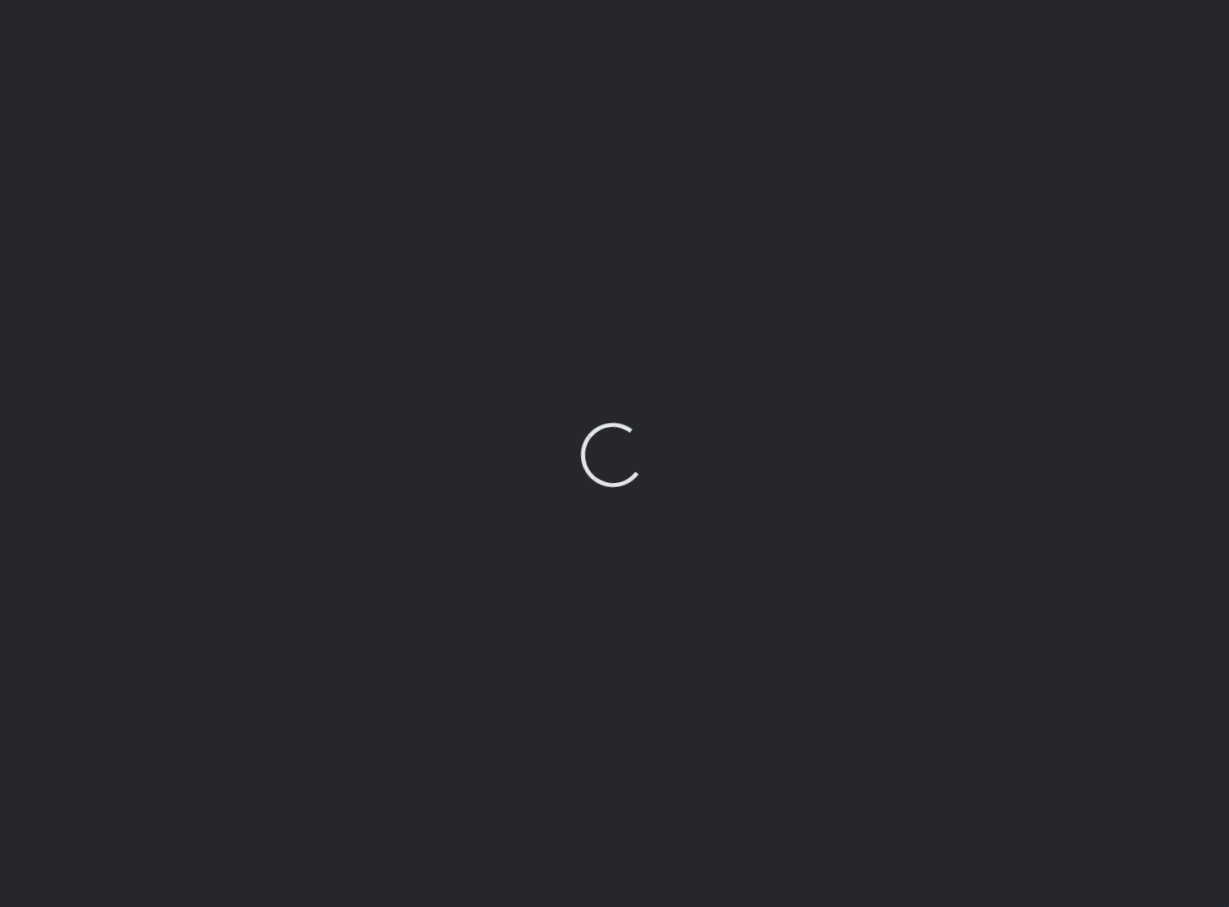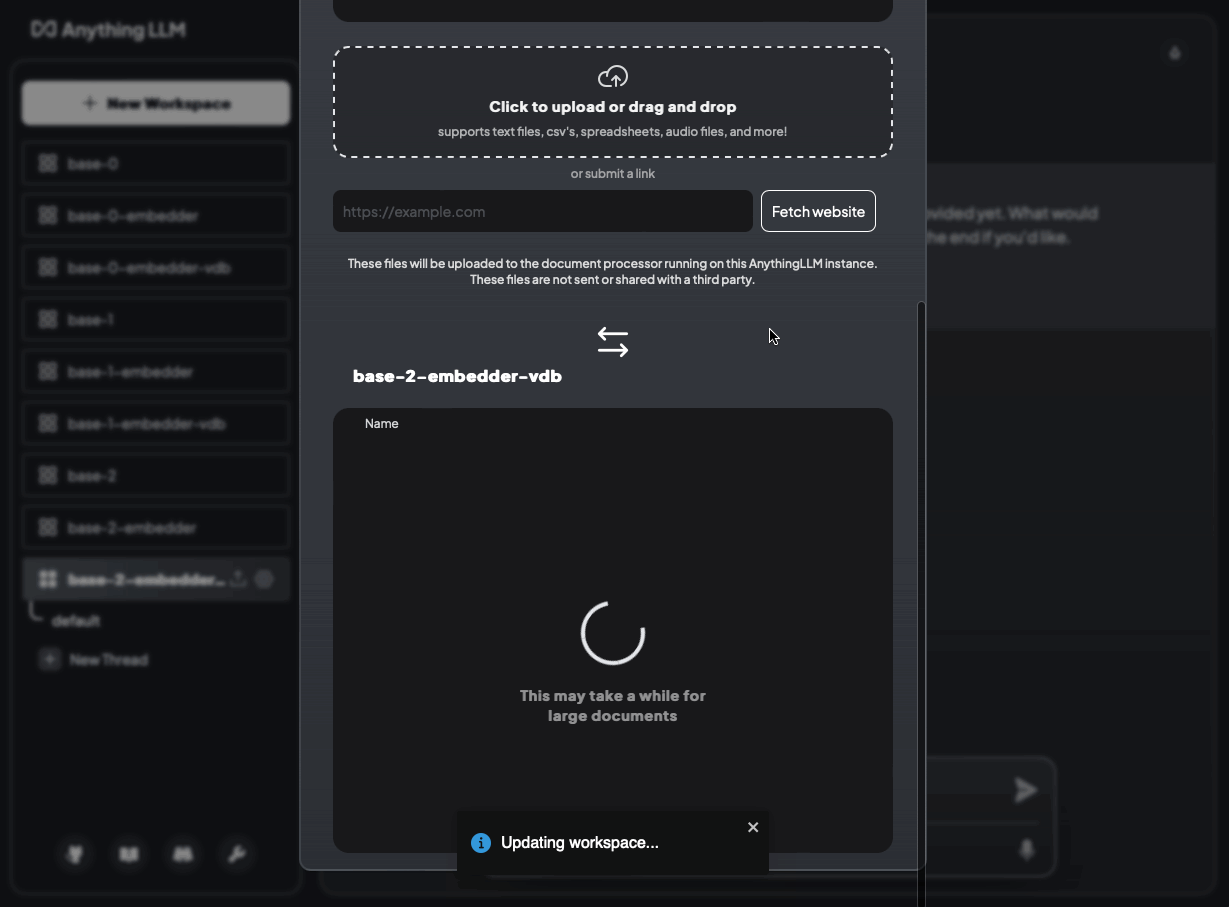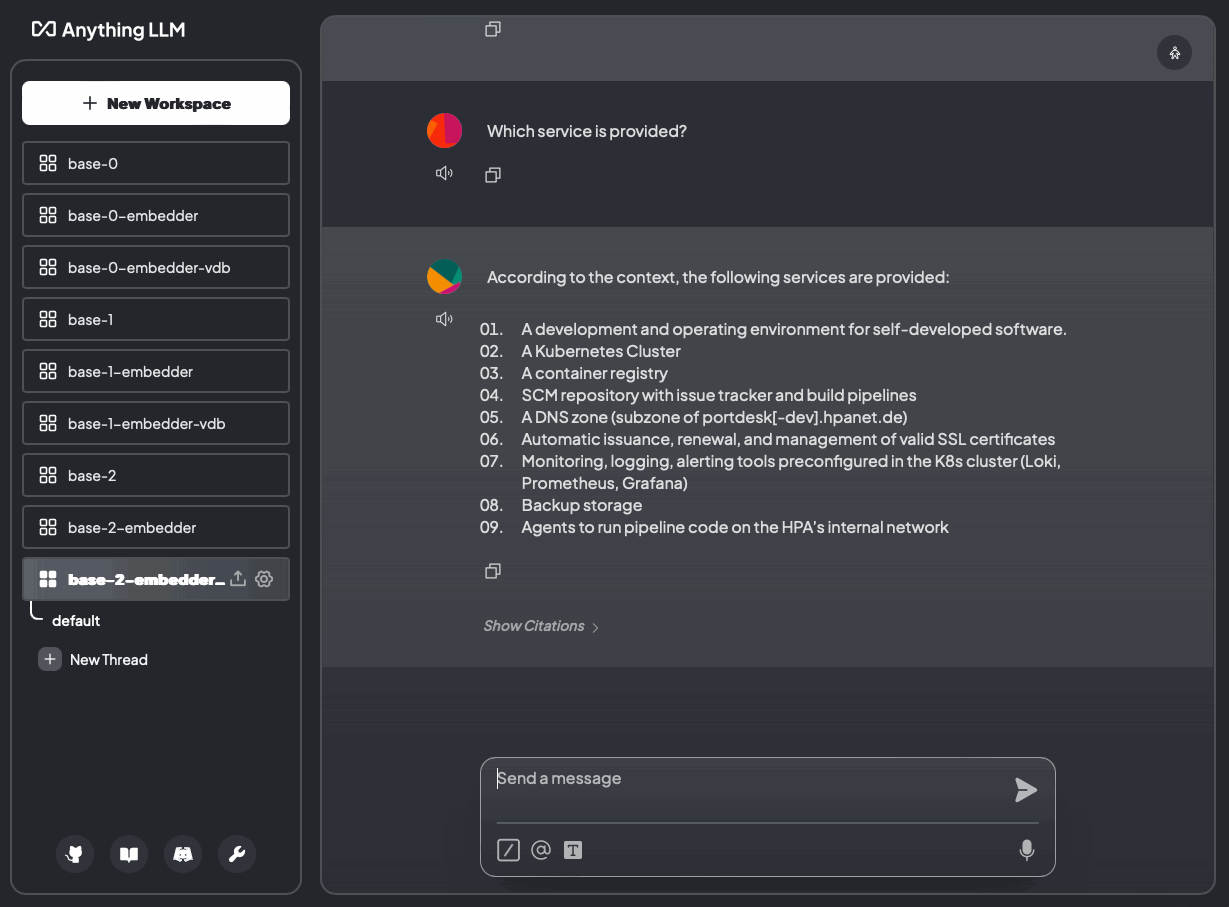
Abbildung 21: Welcher Dienst wird bereitgestellt? Ohne Dokumente und mit Dokumenten (base-2-embedder-vdb)
Und es funktioniert mit ChromaDB. Die Antworten sind anständig, aber Sie müssen etwas Zeit investieren, um das beste Modell für einen fairen Vergleich mit größeren Modellen wie GPT-4o oder GPT-4o-mini zu finden.
Fazit
Zunächst einmal herzlichen Glückwunsch! Sie haben es geschafft!

Dies ist kein Benchmarking verschiedener Lösungen, sondern ein Leitfaden, wie Sie verschiedene Komponenten auf möglichst einfache Weise zusammenstellen können. Hoffentlich haben Sie nun mehrere Lösungen, um loszulegen. Wenn Sie Verbesserungsvorschläge haben oder das Helm-Chart erweitern möchten, um mehr Komponenten zu nutzen, tragen Sie bitte gerne bei. Vergessen Sie nicht, ein ⭐️ zu hinterlassen, um die Sichtbarkeit zu erhöhen und anderen zu helfen.
Meiner Meinung nach sind die größten Herausforderungen für Unternehmen bei der Nutzung von Lösungen wie Anything-LLM:
- Multi-Tenancy (schwierig) – SSO über OIDC: Die Verwaltung von Multi-Tenancy ist komplex und erfordert eine sichere Isolation. OIDC hilft bei der Benutzerauthentifizierung, ist jedoch schwierig für mehrere Mandanten mit Anything-LLM zu konfigurieren. Eine ordnungsgemäße Multi-Tenancy gewährleistet Datensicherheit und -isolation.
- Hochladen in spezifische Buckets und Workspace-Zugriff: Benutzer müssen Dokumente in spezifische Buckets hochladen und über Workspaces mit automatischer Synchronisierung über Git darauf zugreifen können. Dies gewährleistet sichere Speicherung und einfachen Zugriff, während Dokumente stets aktuell bleiben.
- Verhinderung von Datenlecks: Es ist entscheidend sicherzustellen, dass sensible Informationen, wie Gehälter, nicht für unbefugte Personen zugänglich sind. Der Schutz sensibler Daten wahrt die Vertraulichkeit und entspricht den Datenschutzvorschriften.
Sie haben Lösungen wie iitsAI, die diese Herausforderungen effektiv adressieren und sich hervorragend für Unternehmensumgebungen eignen.
Kontaktinformationen
Haben Sie Fragen zum Setup dann kontaktiere mich einfach bei LinkedIn oder du möchtest mehr über unsere Cloud & DevOps Dienstleistungen erfahren dann klicke hier.





